 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Self-Supervised Speech Representations for Improved Dysarthric Speech Recognition
Paper and Code
Apr 04, 2022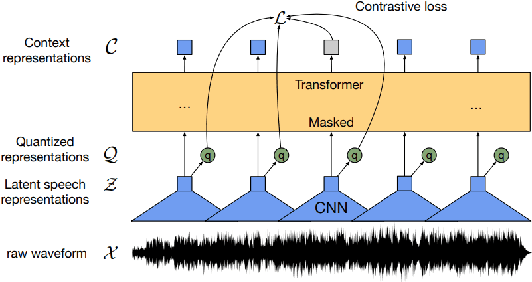

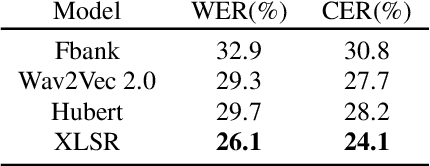
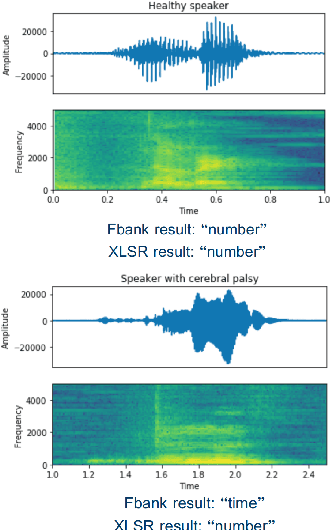
State-of-the-art automatic speech recognition (ASR) systems perform well on healthy speech. However, the performance on impaired speech still remains an issue. The current study explores the usefulness of using Wav2Vec self-supervised speech representations as features for training an ASR system for dysarthric speech. Dysarthric speech recognition is particularly difficult as several aspects of speech such as articulation, prosody and phonation can be impaired. Specifically, we train an acoustic model with features extracted from Wav2Vec, Hubert, and the cross-lingual XLSR model. Results suggest that speech representations pretrained on large unlabelled data can improve word error rate (WER) performance. In particular, features from the multilingual model led to lower WERs than filterbanks (Fbank) or models trained on a single language. Improvements were observed in English speakers with cerebral palsy caused dysarthria (UASpeech corpus), Spanish speakers with Parkinsonian dysarthria (PC-GITA corpus) and Italian speakers with paralysis-based dysarthria (EasyCall corpus). Compared to using Fbank features, XLSR-based features reduced WERs by 6.8%, 22.0%, and 7.0% for the UASpeech, PC-GITA, and EasyCall corpus, respectively.