 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning Strategies to Model Pathological Speech: Effect of Multiple Spectral Resolutions
Paper and Code



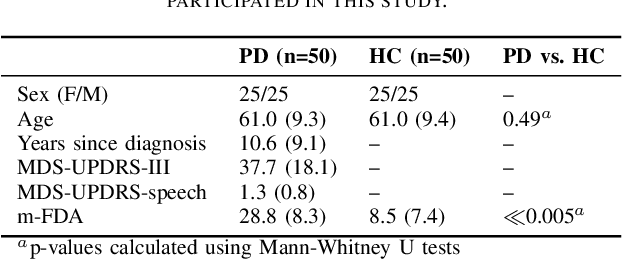
This paper considers a representation learning strategy to model speech signals from patients with Parkinson's disease and cleft lip and palate. In particular, it compares different parametrized representation types such as wideband and narrowband spectrograms, and wavelet-based scalograms, with the goal of quantifying the representation capacity of each. Methods for quantification include the ability of the proposed model to classify different pathologies and the associated disease severity. Additionally, this paper proposes a novel fusion strategy called multi-spectral fusion that combines wideband and narrowband spectral resolutions using a representation learning strategy based on autoencoders. The proposed models are able to classify the speech from Parkinson's disease patients with accuracy up to 95\%. The proposed models were also able to asses the dysarthria severity of Parkinson's disease patients with a Spearman correlation up to 0.75. These results outperform those observed in literature where the same problem was addressed with the same corpus.