 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing domain generalization in fetal brain tissue segmentation: the role of synthetic data generation, intensity clustering and real image fine-tuning
Paper and Code
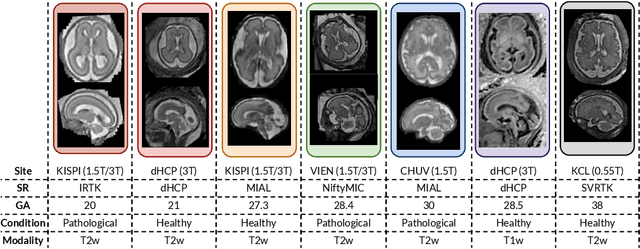
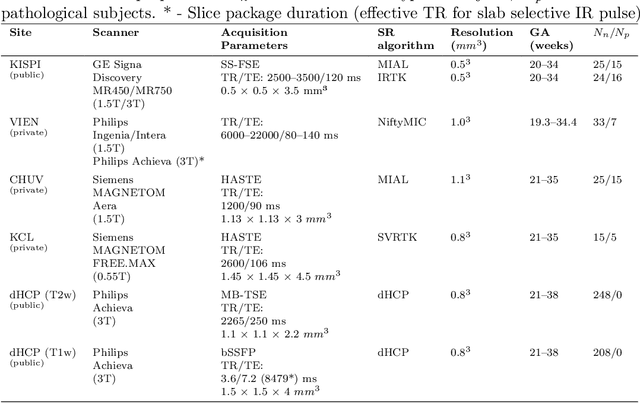
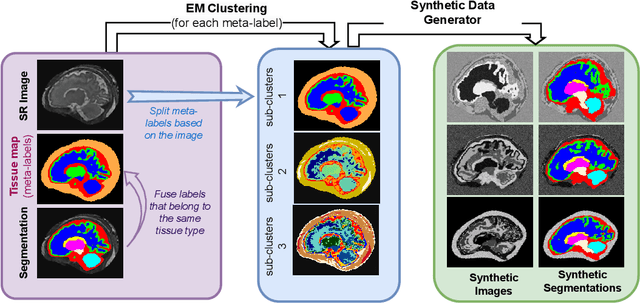
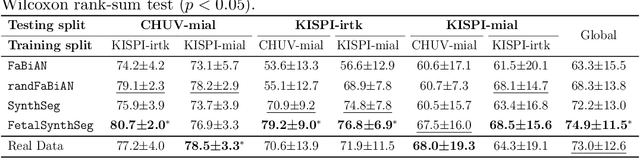
Fetal brain tissue segmentation in magnetic resonance imaging (MRI) is a crucial tool that supports the understanding of neurodevelopment, yet it faces challenges due to the heterogeneity of data coming from different scanners and settings, and due to data scarcity. Recent approaches based on domain randomization, like SynthSeg, have shown a great potential for single source domain generalization, by simulating images with randomized contrast and image resolution from the label maps. In this work, we investigate how to maximize the out-of-domain (OOD) generalization potential of SynthSeg-based methods in fetal brain MRI. Specifically, when studying data generation, we demonstrate that the simple Gaussian mixture models used in SynthSeg enable more robust OOD generalization than physics-informed generation methods. We also investigate how intensity clustering can help create more faithful synthetic images, and observe that it is key to achieving a non-trivial OOD generalization capability when few label classes are available. Finally, by combining for the first time SynthSeg with modern fine-tuning approaches based on weight averaging, we show that fine-tuning a model pre-trained on synthetic data on a few real image-segmentation pairs in a new domain can lead to improvements in the target domain, but also in other domains. We summarize our findings as five key recommendations that we believe can guide practitioners who would like to develop SynthSeg-based approaches in other organs or modalities.