 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PARLO Dementia Corpus: A German Multi-Center Resource for Alzheimer's Disease
Mar 05, 2026Early and accessible detection of Alzheimer's disease (AD) remains a major challenge, as current diagnostic methods often rely on costly and invasive biomarkers. Speech and language analysis has emerged as a promising non-invasive and scalable approach to detecting cognitive impairment, but research in this area is hindered by the lack of publicly available datasets, especially for languages other than English. This paper introduces the PARLO Dementia Corpus (PDC), a new multi-center, clinically validated German resource for AD collected across nine academic memory clinics in Germany. The dataset comprises speech recordings from individuals with AD-related mild cognitive impairment and mild to moderate dementia, as well as cognitively healthy controls. Speech was elicited using a standardized test battery of eight neuropsychological tasks, including confrontation naming, verbal fluency, word repetition, picture description, story reading, and recall tasks. In addition to audio recordings, the dataset includes manually verified transcriptions and detailed demographic, clinical, and biomarker metadata. Baseline experiments on ASR benchmarking, automated test evaluation, and LLM-based classification illustrate the feasibility of automatic, speech-based cognitive assessment and highlight the diagnostic value of recall-driven speech production. The PDC thus establishes the first publicly available German benchmark for multi-modal and cross-lingual research on neurodegenerative diseases.
Infusing Acoustic Pause Context into Text-Based Dementia Assessment
Aug 27, 2024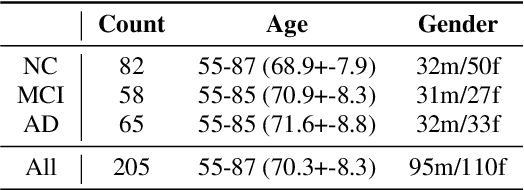
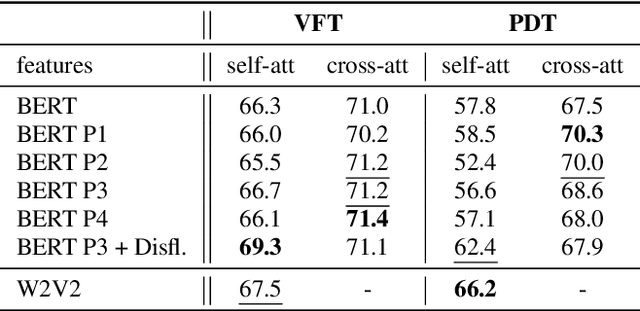
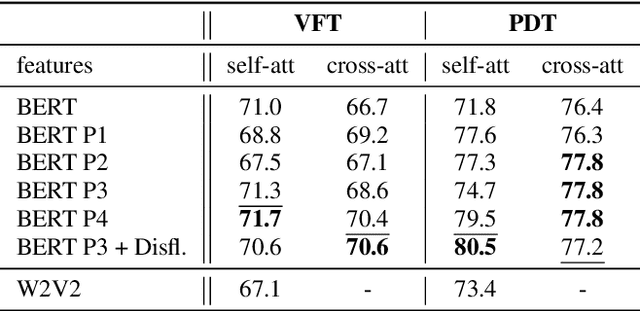
Speech pauses, alongside content and structure, offer a valuable and non-invasive biomarker for detecting dementia. This work investigates the use of pause-enriched transcripts in transformer-based language models to differentiate the cognitive states of subjects with no cognitive impairment, mild cognitive impairment, and Alzheimer's dementia based on their speech from a clinical assessment. We address three binary classification tasks: Onset, monitoring, and dementia exclusion. The performance is evaluated through experiments on a German Verbal Fluency Test and a Picture Description Test, comparing the model's effectiveness across different speech production contexts. Starting from a textual baseline, we investigate the effect of incorporation of pause information and acoustic context. We show the test should be chosen depending on the task, and similarly, lexical pause information and acoustic cross-attention contribute differently.
Classifying Dementia in the Presence of Depression: A Cross-Corpus Study
Aug 16, 2023Automated dementia screening enables early detection and intervention, reducing costs to healthcare systems and increasing quality of life for those affected. Depression has shared symptoms with dementia, adding complexity to diagnoses. The research focus so far has been on binary classification of dementia (DEM) and healthy controls (HC) using speech from picture description tests from a single dataset. In this work, we apply established baseline systems to discriminate cognitive impairment in speech from the semantic Verbal Fluency Test and the Boston Naming Test using text, audio and emotion embeddings in a 3-class classification problem (HC vs. MCI vs. DEM). We perform cross-corpus and mixed-corpus experiments on two independently recorded German datasets to investigate generalization to larger populations and different recording conditions. In a detailed error analysis, we look at depression as a secondary diagnosis to understand what our classifiers actually learn.
A Stutter Seldom Comes Alone -- Cross-Corpus Stuttering Detection as a Multi-label Problem
May 30, 2023Most stuttering detection and classification research has viewed stuttering as a multi-class classification problem or a binary detection task for each dysfluency type; however, this does not match the nature of stuttering, in which one dysfluency seldom comes alone but rather co-occurs with others. This paper explores multi-language and cross-corpus end-to-end stuttering detection as a multi-label problem using a modified wav2vec 2.0 system with an attention-based classification head and multi-task learning. We evaluate the method using combinations of three datasets containing English and German stuttered speech, one containing speech modified by fluency shaping. The experimental results and an error analysis show that multi-label stuttering detection systems trained on cross-corpus and multi-language data achieve competitive results but performance on samples with multiple labels stays below over-all detection results.
Dysfluencies Seldom Come Alone -- Detection as a Multi-Label Problem
Oct 28, 2022


Specially adapted speech recognition models are necessary to handle stuttered speech. For these to be used in a targeted manner, stuttered speech must be reliably detected. Recent works have treated stuttering as a multi-class classification problem or viewed detecting each dysfluency type as an isolated task; that does not capture the nature of stuttering, where one dysfluency seldom comes alone, i.e., co-occurs with others. This work explores an approach based on a modified wav2vec 2.0 system for end-to-end stuttering detection and classification as a multi-label problem. The method is evaluated on combinations of three datasets containing English and German stuttered speech, yielding state-of-the-art results for stuttering detection on the SEP-28k-Extended dataset. Experimental results provide evidence for the transferability of features and the generalizability of the method across datasets and languages.
KSoF: The Kassel State of Fluency Dataset -- A Therapy Centered Dataset of Stuttering
Mar 10, 2022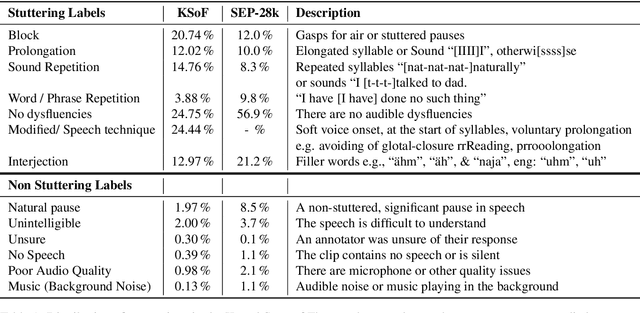

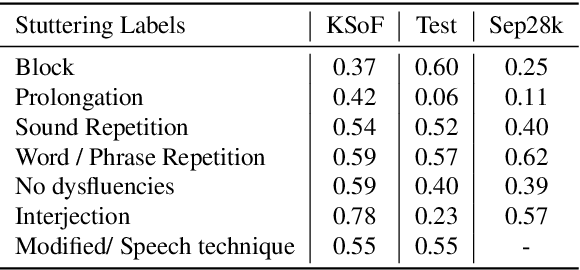
Stuttering is a complex speech disorder that negatively affects an individual's ability to communicate effectively. Persons who stutter (PWS) often suffer considerably under the condition and seek help through therapy. Fluency shaping is a therapy approach where PWSs learn to modify their speech to help them to overcome their stutter. Mastering such speech techniques takes time and practice, even after therapy. Shortly after therapy, success is evaluated highly, but relapse rates are high. To be able to monitor speech behavior over a long time, the ability to detect stuttering events and modifications in speech could help PWSs and speech pathologists to track the level of fluency. Monitoring could create the ability to intervene early by detecting lapses in fluency. To the best of our knowledge, no public dataset is available that contains speech from people who underwent stuttering therapy that changed the style of speaking. This work introduces the Kassel State of Fluency (KSoF), a therapy-based dataset containing over 5500 clips of PWSs. The clips were labeled with six stuttering-related event types: blocks, prolongations, sound repetitions, word repetitions, interjections, and - specific to therapy - speech modifications. The audio was recorded during therapy sessions at the Institut der Kasseler Stottertherapie. The data will be made available for research purposes upon request.
Towards Automated Assessment of Stuttering and Stuttering Therapy
Jun 16, 2020
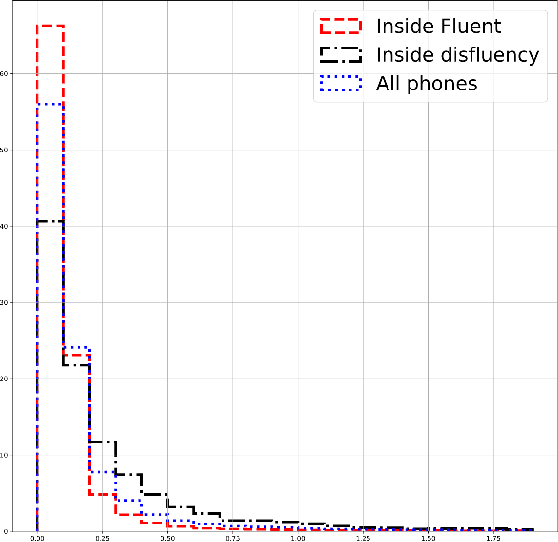
Stuttering is a complex speech disorder that can be identified by repetitions, prolongations of sounds, syllables or words, and blocks while speaking. Severity assessment is usually done by a speech therapist. While attempts at automated assessment were made, it is rarely used in therapy. Common methods for the assessment of stuttering severity include percent stuttered syllables (% SS), the average of the three longest stuttering symptoms during a speech task, or the recently introduced Speech Efficiency Score (SES). This paper introduces the Speech Control Index (SCI), a new method to evaluate the severity of stuttering. Unlike SES, it can also be used to assess therapy success for fluency shaping. We evaluate both SES and SCI on a new comprehensively labeled dataset containing stuttered German speech of clients prior to, during, and after undergoing stuttering therapy. Phone alignments of an automatic speech recognition system are statistically evaluated in relation to their relative position to labeled stuttering events. The results indicate that phone length distributions differ with respect to their position in and around labeled stuttering events