 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Adaptation for End-To-End Speech Recognition Systems in Noisy Environments
Paper and Code

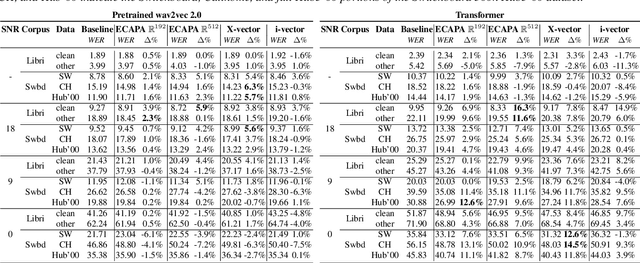
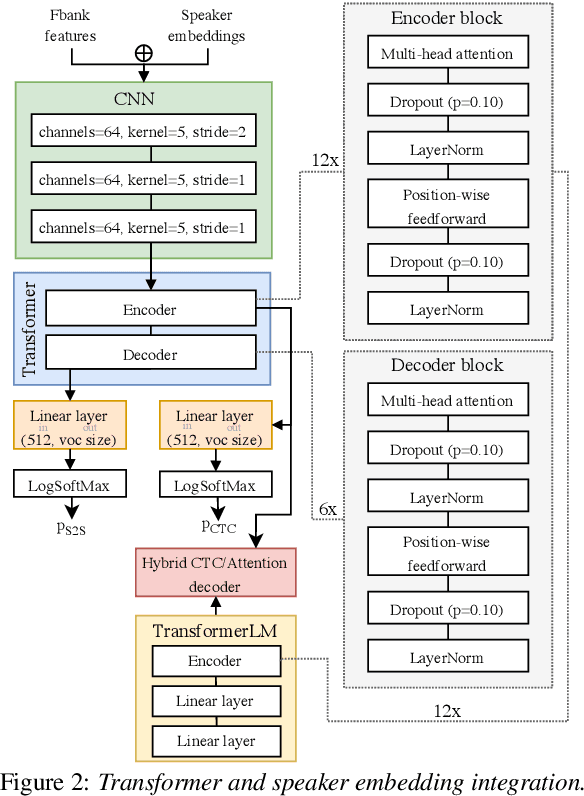
We analyze the impact of speaker adaptation in end-to-end architectures based on transformers and wav2vec 2.0 under different noise conditions. We demonstrate that the proven method of concatenating speaker vectors to the acoustic features and supplying them as an auxiliary model input remains a viable option to increase the robustness of end-to-end architectures. By including speaker embeddings obtained from x-vector and ECAPA-TDNN models, we achieve relative word error rate improvements of up to 9.6% on LibriSpeech and up to 14.5% on Switchboard. The effect on transformer-based architectures is approximately inversely proportional to the signal-to-noise ratio (SNR) and is strongest in heavily noised environments ($SNR=0$). The most substantial benefit of speaker adaption in systems based on wav2vec 2.0 can be achieved under moderate noise conditions ($SNR\geq18$). We also find that x-vectors tend to yield larger improvements than ECAPA-TDNN embeddings.