 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized Speculative Sampling for GPU Hardware Accelerators
Paper and Code
Jun 16, 2024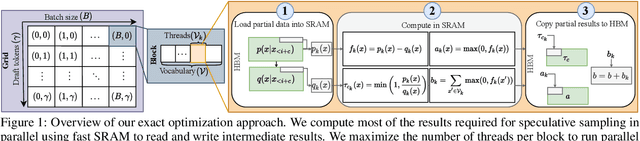
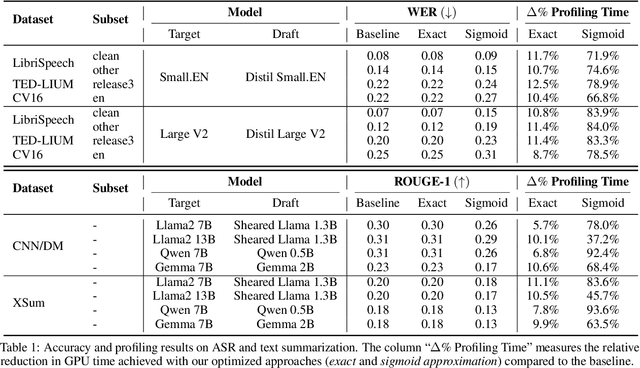


In this work, we optimize speculative sampling for parallel hardware accelerators to improve sampling speed. We notice that substantial portions of the intermediate matrices necessary for speculative sampling can be computed concurrently. This allows us to distribute the workload across multiple GPU threads, enabling simultaneous operations on matrix segments within thread blocks. Additionally, we use fast on-chip memory to store intermediate results, thereby minimizing the frequency of slow read and write operations across different types of memory. This results in profiling time improvements ranging from 6% to 13% relative to the baseline implementation, without compromising accuracy. To further accelerate speculative sampling, probability distributions parameterized by softmax are approximated by sigmoid. This approximation approach results in significantly greater relative improvements in profiling time, ranging from 37% to 94%, with a slight decline in accuracy. We conduct extensive experiments on both automatic speech recognition and summarization tasks to validate the effectiveness of our optimization methods.