 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Qualitative and Quantitative Safety Verification of DNN-Controlled Systems
Apr 02, 2024The rapid advance of deep reinforcement learning techniques enables the oversight of safety-critical systems through the utilization of Deep Neural Networks (DNNs). This underscores the pressing need to promptly establish certified safety guarantees for such DNN-controlled systems. Most of the existing verification approaches rely on qualitative approaches, predominantly employing reachability analysis. However, qualitative verification proves inadequate for DNN-controlled systems as their behaviors exhibit stochastic tendencies when operating in open and adversarial environments. In this paper, we propose a novel framework for unifying both qualitative and quantitative safety verification problems of DNN-controlled systems. This is achieved by formulating the verification tasks as the synthesis of valid neural barrier certificates (NBCs). Initially, the framework seeks to establish almost-sure safety guarantees through qualitative verification. In cases where qualitative verification fails, our quantitative verification method is invoked, yielding precise lower and upper bounds on probabilistic safety across both infinite and finite time horizons. To facilitate the synthesis of NBCs, we introduce their $k$-inductive variants. We also devise a simulation-guided approach for training NBCs, aiming to achieve tightness in computing precise certified lower and upper bounds. We prototype our approach into a tool called $\textsf{UniQQ}$ and showcase its efficacy on four classic DNN-controlled systems.
Robustness Verification of Deep Reinforcement Learning Based Control Systems using Reward Martingales
Dec 15, 2023Deep Reinforcement Learning (DRL) has gained prominence as an effective approach for control systems. However, its practical deployment is impeded by state perturbations that can severely impact system performance. Addressing this critical challenge requires robustness verification about system performance, which involves tackling two quantitative questions: (i) how to establish guaranteed bounds for expected cumulative rewards, and (ii) how to determine tail bounds for cumulative rewards. In this work, we present the first approach for robustness verification of DRL-based control systems by introducing reward martingales, which offer a rigorous mathematical foundation to characterize the impact of state perturbations on system performance in terms of cumulative rewards. Our verified results provide provably quantitative certificates for the two questions. We then show that reward martingales can be implemented and trained via neural networks, against different types of control policies. Experimental results demonstrate that our certified bounds tightly enclose simulation outcomes on various DRL-based control systems, indicating the effectiveness and generality of the proposed approach.
BBReach: Tight and Scalable Black-Box Reachability Analysis of Deep Reinforcement Learning Systems
Nov 21, 2022

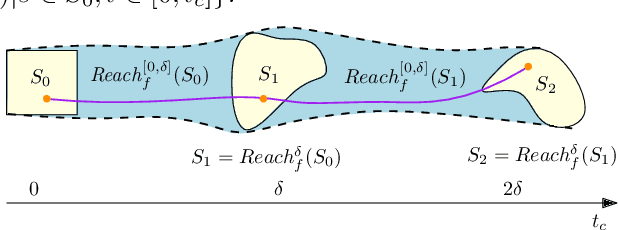

Reachability analysis is a promising technique to automatically prove or disprove the reliability and safety of AI-empowered software systems that are developed by using Deep Reinforcement Learning (DRL). Existing approaches suffer however from limited scalability and large overestimation as they must over-approximate the complex and almost inexplicable system components, namely deep neural networks (DNNs). In this paper we propose a novel, tight and scalable reachability analysis approach for DRL systems. By training on abstract states, our approach treats the embedded DNNs as black boxes to avoid the over-approximation for neural networks in computing reachable sets. To tackle the state explosion problem inherent to abstraction-based approaches, we devise a novel adjacent interval aggregation algorithm which balances the growth of abstract states and the overestimation caused by the abstraction. We implement a tool, called BBReach, and assess it on an extensive benchmark of control systems to demonstrate its tightness, scalability, and efficiency.