 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling CMF Estimation in Data-Constrained Scenarios: A Semantic-Encoding Knowledge Mining Model
Paper and Code
Nov 15, 2023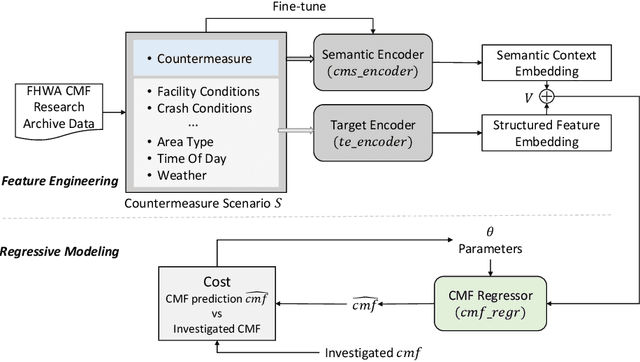

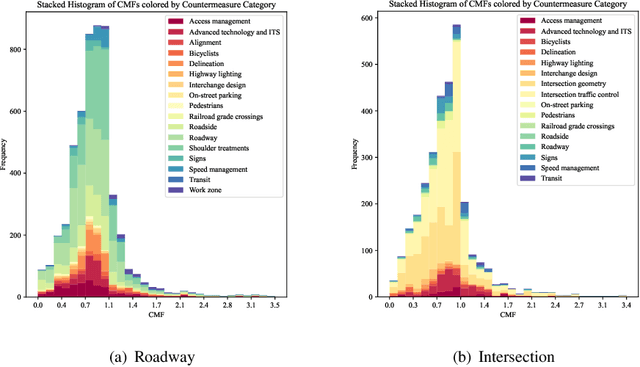
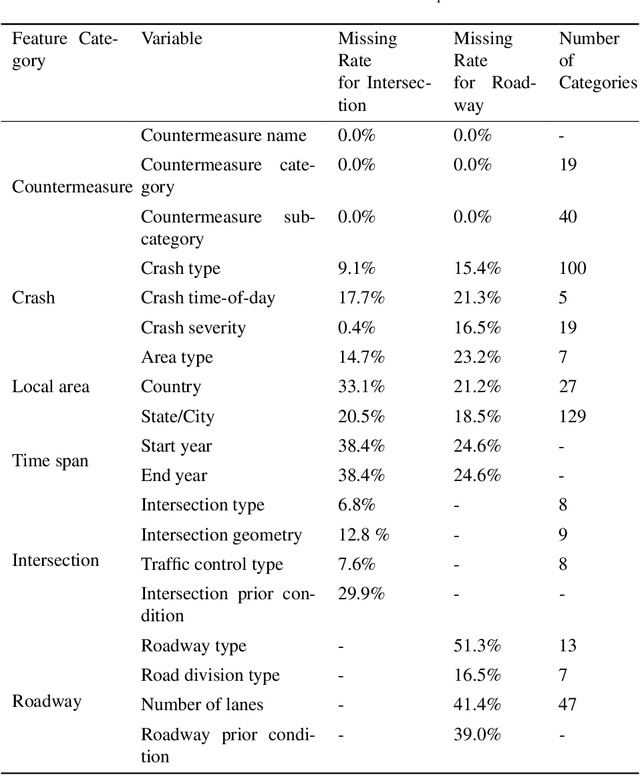
Precise estimation of Crash Modification Factors (CMFs) is central to evaluating the effectiveness of various road safety treatments and prioritizing infrastructure investment accordingly. While customized study for each countermeasure scenario is desired, the conventional CMF estimation approaches rely heavily on the availability of crash data at given sites. This not only makes the estimation costly, but the results are also less transferable, since the intrinsic similarities between different safety countermeasure scenarios are not fully explored. Aiming to fill this gap, this study introduces a novel knowledge-mining framework for CMF prediction. This framework delves into the connections of existing countermeasures and reduces the reliance of CMF estimation on crash data availability and manual data collection. Specifically, it draws inspiration from human comprehension processes and introduces advanced Natural Language Processing (NLP) techniques to extract intricate variations and patterns from existing CMF knowledge. It effectively encodes unstructured countermeasure scenarios into machine-readable representations and models the complex relationships between scenarios and CMF values. This new data-driven framework provides a cost-effective and adaptable solution that complements the case-specific approaches for CMF estimation, which is particularly beneficial when availability of crash data or time imposes constraints. Experimental validation using real-world CMF Clearinghouse data demonstrates the effectiveness of this new approach, which shows significant accuracy improvements compared to baseline methods. This approach provides insights into new possibilities of harnessing accumulated transportation knowledge in various applications.