 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Recovery of Non-Random Missing Multidimensional Time Series via Temporal Isometric Delay-Embedding Transform
Dec 11, 2025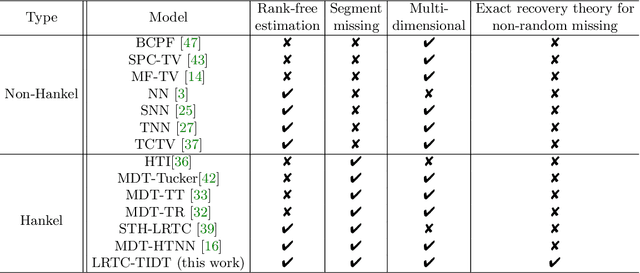
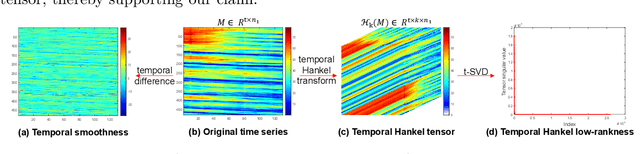
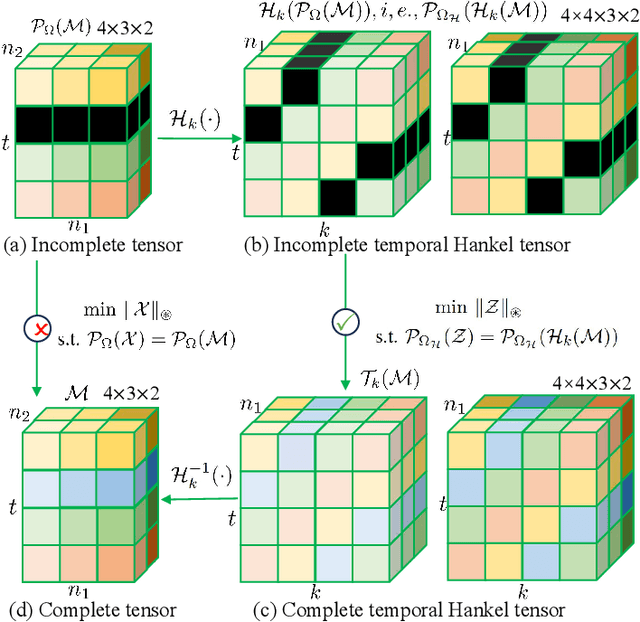
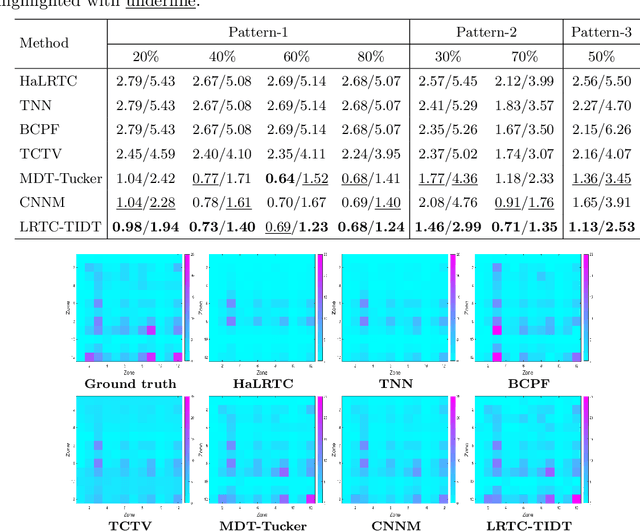
Non-random missing data is a ubiquitous yet undertreated flaw in multidimensional time series, fundamentally threatening the reliability of data-driven analysis and decision-making. Pure low-rank tensor completion, as a classical data recovery method, falls short in handling non-random missingness, both methodologically and theoretically. Hankel-structured tensor completion models provide a feasible approach for recovering multidimensional time series with non-random missing patterns. However, most Hankel-based multidimensional data recovery methods both suffer from unclear sources of Hankel tensor low-rankness and lack an exact recovery theory for non-random missing data. To address these issues, we propose the temporal isometric delay-embedding transform, which constructs a Hankel tensor whose low-rankness is naturally induced by the smoothness and periodicity of the underlying time series. Leveraging this property, we develop the \textit{Low-Rank Tensor Completion with Temporal Isometric Delay-embedding Transform} (LRTC-TIDT) model, which characterizes the low-rank structure under the \textit{Tensor Singular Value Decomposition} (t-SVD) framework. Once the prescribed non-random sampling conditions and mild incoherence assumptions are satisfied, the proposed LRTC-TIDT model achieves exact recovery, as confirmed by simulation experiments under various non-random missing patterns. Furthermore, LRTC-TIDT consistently outperforms existing tensor-based methods across multiple real-world tasks, including network flow reconstruction, urban traffic estimation, and temperature field prediction. Our implementation is publicly available at https://github.com/HaoShu2000/LRTC-TIDT.
Edge-Boundary-Texture Loss: A Tri-Class Generalization of Weighted Binary Cross-Entropy for Enhanced Edge Detection
Jul 09, 2025Edge detection (ED) remains a fundamental task in computer vision, yet its performance is often hindered by the ambiguous nature of non-edge pixels near object boundaries. The widely adopted Weighted Binary Cross-Entropy (WBCE) loss treats all non-edge pixels uniformly, overlooking the structural nuances around edges and often resulting in blurred predictions. In this paper, we propose the Edge-Boundary-Texture (EBT) loss, a novel objective that explicitly divides pixels into three categories, edge, boundary, and texture, and assigns each a distinct supervisory weight. This tri-class formulation enables more structured learning by guiding the model to focus on both edge precision and contextual boundary localization. We theoretically show that the EBT loss generalizes the WBCE loss, with the latter becoming a limit case. Extensive experiments across multiple benchmarks demonstrate the superiority of the EBT loss both quantitatively and perceptually. Furthermore, the consistent use of unified hyperparameters across all models and datasets, along with robustness to their moderate variations, indicates that the EBT loss requires minimal fine-tuning and is easily deployable in practice.
Binarization-Aware Adjuster: Bridging Continuous Optimization and Binary Inference in Edge Detection
Jun 14, 2025Image edge detection (ED) faces a fundamental mismatch between training and inference: models are trained using continuous-valued outputs but evaluated using binary predictions. This misalignment, caused by the non-differentiability of binarization, weakens the link between learning objectives and actual task performance. In this paper, we propose a theoretical method to design a Binarization-Aware Adjuster (BAA), which explicitly incorporates binarization behavior into gradient-based optimization. At the core of BAA is a novel loss adjustment mechanism based on a Distance Weight Function (DWF), which reweights pixel-wise contributions according to their correctness and proximity to the decision boundary. This emphasizes decision-critical regions while down-weighting less influential ones. We also introduce a self-adaptive procedure to estimate the optimal binarization threshold for BAA, further aligning training dynamics with inference behavior. Extensive experiments across various architectures and datasets demonstrate the effectiveness of our approach. Beyond ED, BAA offers a generalizable strategy for bridging the gap between continuous optimization and discrete evaluation in structured prediction tasks.
Hyperspectral Anomaly Detection Fused Unified Nonconvex Tensor Ring Factors Regularization
May 23, 2025In recent years, tensor decomposition-based approaches for hyperspectral anomaly detection (HAD) have gained significant attention in the field of remote sensing. However, existing methods often fail to fully leverage both the global correlations and local smoothness of the background components in hyperspectral images (HSIs), which exist in both the spectral and spatial domains. This limitation results in suboptimal detection performance. To mitigate this critical issue, we put forward a novel HAD method named HAD-EUNTRFR, which incorporates an enhanced unified nonconvex tensor ring (TR) factors regularization. In the HAD-EUNTRFR framework, the raw HSIs are first decomposed into background and anomaly components. The TR decomposition is then employed to capture the spatial-spectral correlations within the background component. Additionally, we introduce a unified and efficient nonconvex regularizer, induced by tensor singular value decomposition (TSVD), to simultaneously encode the low-rankness and sparsity of the 3-D gradient TR factors into a unique concise form. The above characterization scheme enables the interpretable gradient TR factors to inherit the low-rankness and smoothness of the original background. To further enhance anomaly detection, we design a generalized nonconvex regularization term to exploit the group sparsity of the anomaly component. To solve the resulting doubly nonconvex model, we develop a highly efficient optimization algorithm based on the alternating direction method of multipliers (ADMM) framework. Experimental results on several benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art (SOTA) approaches in terms of detection accuracy.
Guaranteed Multidimensional Time Series Prediction via Deterministic Tensor Completion Theory
Jan 26, 2025In recent years, the prediction of multidimensional time series data has become increasingly important due to its wide-ranging applications. Tensor-based prediction methods have gained attention for their ability to preserve the inherent structure of such data. However, existing approaches, such as tensor autoregression and tensor decomposition, often have consistently failed to provide clear assertions regarding the number of samples that can be exactly predicted. While matrix-based methods using nuclear norms address this limitation, their reliance on matrices limits accuracy and increases computational costs when handling multidimensional data. To overcome these challenges, we reformulate multidimensional time series prediction as a deterministic tensor completion problem and propose a novel theoretical framework. Specifically, we develop a deterministic tensor completion theory and introduce the Temporal Convolutional Tensor Nuclear Norm (TCTNN) model. By convolving the multidimensional time series along the temporal dimension and applying the tensor nuclear norm, our approach identifies the maximum forecast horizon for exact predictions. Additionally, TCTNN achieves superior performance in prediction accuracy and computational efficiency compared to existing methods across diverse real-world datasets, including climate temperature, network flow, and traffic ride data. Our implementation is publicly available at https://github.com/HaoShu2000/TCTNN.
Pixel-Wise Feature Selection for Perceptual Edge Detection without post-processing
Jan 05, 2025



Although deep convolutional neutral networks (CNNs) have significantly enhanced performance in image edge detection (ED), current models remain highly dependent on post-processing techniques such as non-maximum suppression (NMS), and often fail to deliver satisfactory perceptual results, while the performance will deteriorate significantly if the allowed error toleration distance decreases. These limitations arise from the uniform fusion of features across all pixels, regardless of their specific characteristics, such as the distinction between textural and edge areas. If the features extracted by the ED models are selected more meticulously and encompass greater diversity, the resulting predictions are expected to be more accurate and perceptually meaningful. Motivated by this observation, this paper proposes a novel feature selection paradigm for deep networks that facilitates the differential selection of features and can be seamlessly integrated into existing ED models. By incorporating this additional structure, the performance of conventional ED models is substantially enhanced without post-processing, while simultaneously enhancing the perceptual quality of the predictions. Extensive experimental evaluations validate the effectiveness of the proposed model.
Improving Generated and Retrieved Knowledge Combination Through Zero-shot Generation
Dec 25, 2024



Open-domain Question Answering (QA) has garnered substantial interest by combining the advantages of faithfully retrieved passages and relevant passages generated through Large Language Models (LLMs). However, there is a lack of definitive labels available to pair these sources of knowledge. In order to address this issue, we propose an unsupervised and simple framework called Bi-Reranking for Merging Generated and Retrieved Knowledge (BRMGR), which utilizes re-ranking methods for both retrieved passages and LLM-generated passages. We pair the two types of passages using two separate re-ranking methods and then combine them through greedy matching. We demonstrate that BRMGR is equivalent to employing a bipartite matching loss when assigning each retrieved passage with a corresponding LLM-generated passage. The application of our model yielded experimental results from three datasets, improving their performance by +1.7 and +1.6 on NQ and WebQ datasets, respectively, and obtaining comparable result on TriviaQA dataset when compared to competitive baselines.
More precise edge detections
Jul 29, 2024Image Edge detection (ED) is a base task in computer vision. While the performance of the ED algorithm has been improved greatly by introducing CNN-based models, current models still suffer from unsatisfactory precision rates especially when only a low error toleration distance is allowed. Therefore, model architecture for more precise predictions still needs an investigation. On the other hand, the unavoidable noise training data provided by humans would lead to unsatisfactory model predictions even when inputs are edge maps themselves, which also needs improvement. In this paper, more precise ED models are presented with cascaded skipping density blocks (CSDB). Our models obtain state-of-the-art(SOTA) predictions in several datasets, especially in average precision rate (AP), which is confirmed by extensive experiments. Moreover, our models do not include down-sample operations, demonstrating those widely believed operations are not necessary. Also, a novel modification on data augmentation for training is employed, which allows noiseless data to be employed in model training and thus improves the performance of models predicting on edge maps themselves.
SDC-HSDD-NDSA: Structure Detecting Cluster by Hierarchical Secondary Directed Differential with Normalized Density and Self-Adaption
Jul 05, 2023Density-based clustering could be the most popular clustering algorithm since it can identify clusters of arbitrary shape as long as different (high-density) clusters are separated by low-density regions. However, the requirement of the separateness of clusters by low-density regions is not trivial since a high-density region might have different structures which should be clustered into different groups. Such a situation demonstrates the main flaw of all previous density-based clustering algorithms we have known--structures in a high-density cluster could not be detected. Therefore, this paper aims to provide a density-based clustering scheme that not only has the ability previous ones have but could also detect structures in a high-density region not separated by low-density ones. The algorithm employs secondary directed differential, hierarchy, normalized density, as well as the self-adaption coefficient, and thus is called Structure Detecting Cluster by Hierarchical Secondary Directed Differential with Normalized Density and Self-Adaption, dubbed by SDC-HSDD-NDSA for short. To illustrate its effectiveness, we run the algorithm in several data sets. The results verify its validity in structure detection, robustness over noises, as well as independence of granularities, and demonstrate that it could outperform previous ones. The Python code of the paper could be found on https://github.com/Hao-B-Shu/SDC-HSDD-NDSA.