 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Knowledge Retrieval with In-Context Learning and Semantic Search through Generative AI
Jun 13, 2024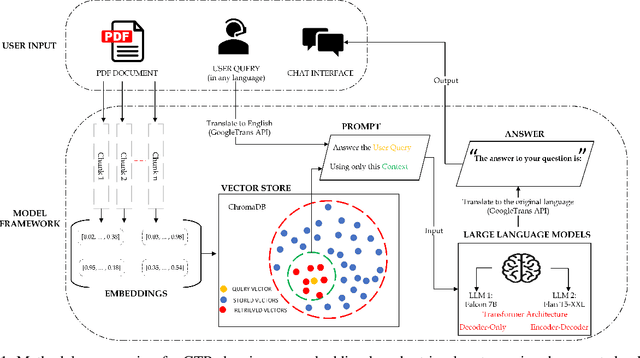

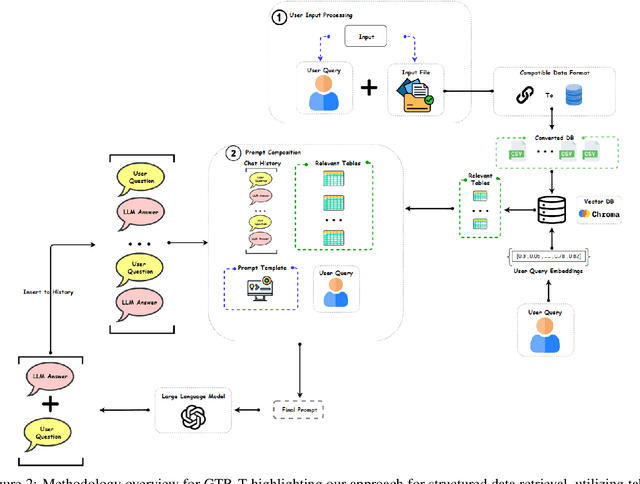

Retrieving and extracting knowledge from extensive research documents and large databases presents significant challenges for researchers, students, and professionals in today's information-rich era. Existing retrieval systems, which rely on general-purpose Large Language Models (LLMs), often fail to provide accurate responses to domain-specific inquiries. Additionally, the high cost of pretraining or fine-tuning LLMs for specific domains limits their widespread adoption. To address these limitations, we propose a novel methodology that combines the generative capabilities of LLMs with the fast and accurate retrieval capabilities of vector databases. This advanced retrieval system can efficiently handle both tabular and non-tabular data, understand natural language user queries, and retrieve relevant information without fine-tuning. The developed model, Generative Text Retrieval (GTR), is adaptable to both unstructured and structured data with minor refinement. GTR was evaluated on both manually annotated and public datasets, achieving over 90% accuracy and delivering truthful outputs in 87% of cases. Our model achieved state-of-the-art performance with a Rouge-L F1 score of 0.98 on the MSMARCO dataset. The refined model, Generative Tabular Text Retrieval (GTR-T), demonstrated its efficiency in large database querying, achieving an Execution Accuracy (EX) of 0.82 and an Exact-Set-Match (EM) accuracy of 0.60 on the Spider dataset, using an open-source LLM. These efforts leverage Generative AI and In-Context Learning to enhance human-text interaction and make advanced AI capabilities more accessible. By integrating robust retrieval systems with powerful LLMs, our approach aims to democratize access to sophisticated AI tools, improving the efficiency, accuracy, and scalability of AI-driven information retrieval and database querying.
Rare Class Prediction Model for Smart Industry in Semiconductor Manufacturing
Jun 06, 2024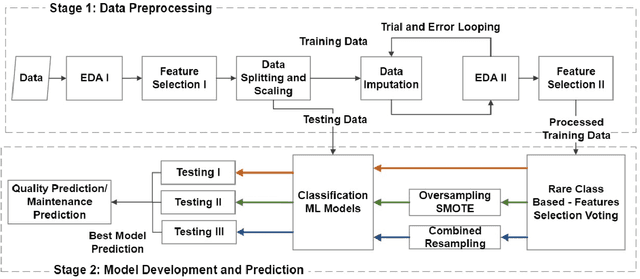
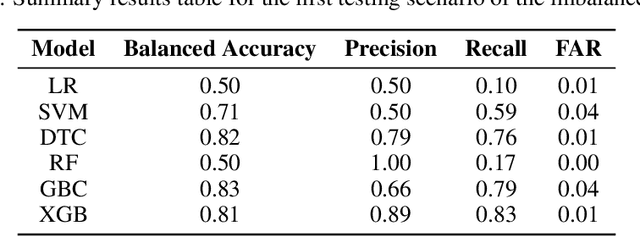
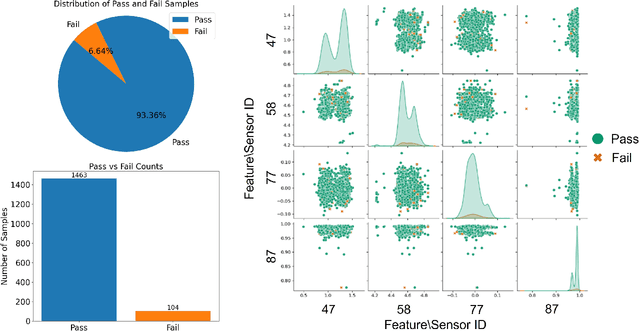
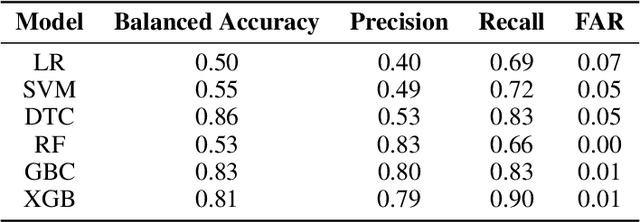
The evolution of industry has enabled the integration of physical and digital systems, facilitating the collection of extensive data on manufacturing processes. This integration provides a reliable solution for improving process quality and managing equipment health. However, data collected from real manufacturing processes often exhibit challenging properties, such as severe class imbalance, high rates of missing values, and noisy features, which hinder effective machine learning implementation. In this study, a rare class prediction approach is developed for in situ data collected from a smart semiconductor manufacturing process. The primary objective is to build a model that addresses issues of noise and class imbalance, enhancing class separation. The developed approach demonstrated promising results compared to existing literature, which would allow the prediction of new observations that could give insights into future maintenance plans and production quality. The model was evaluated using various performance metrics, with ROC curves showing an AUC of 0.95, a precision of 0.66, and a recall of 0.96
GAMedX: Generative AI-based Medical Entity Data Extractor Using Large Language Models
May 31, 2024



In the rapidly evolving field of healthcare and beyond, the integration of generative AI in Electronic Health Records (EHRs) represents a pivotal advancement, addressing a critical gap in current information extraction techniques. This paper introduces GAMedX, a Named Entity Recognition (NER) approach utilizing Large Language Models (LLMs) to efficiently extract entities from medical narratives and unstructured text generated throughout various phases of the patient hospital visit. By addressing the significant challenge of processing unstructured medical text, GAMedX leverages the capabilities of generative AI and LLMs for improved data extraction. Employing a unified approach, the methodology integrates open-source LLMs for NER, utilizing chained prompts and Pydantic schemas for structured output to navigate the complexities of specialized medical jargon. The findings reveal significant ROUGE F1 score on one of the evaluation datasets with an accuracy of 98\%. This innovation enhances entity extraction, offering a scalable, cost-effective solution for automated forms filling from unstructured data. As a result, GAMedX streamlines the processing of unstructured narratives, and sets a new standard in NER applications, contributing significantly to theoretical and practical advancements beyond the medical technology sphere.