 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Explanation Constraints
Paper and Code
Mar 25, 2023
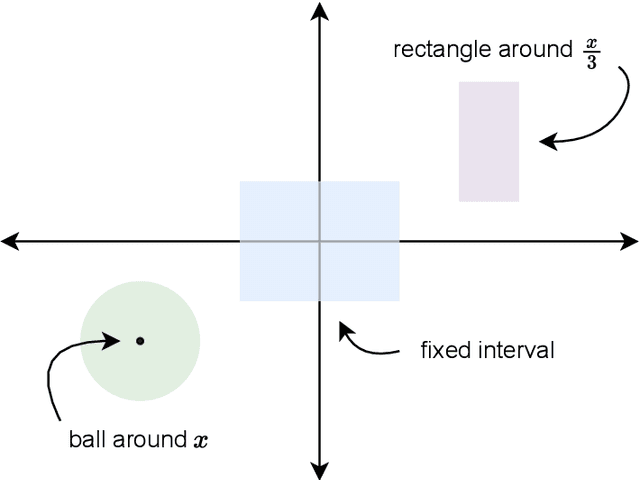
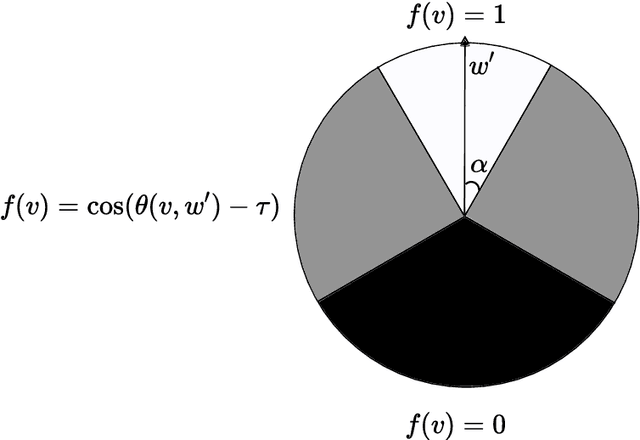
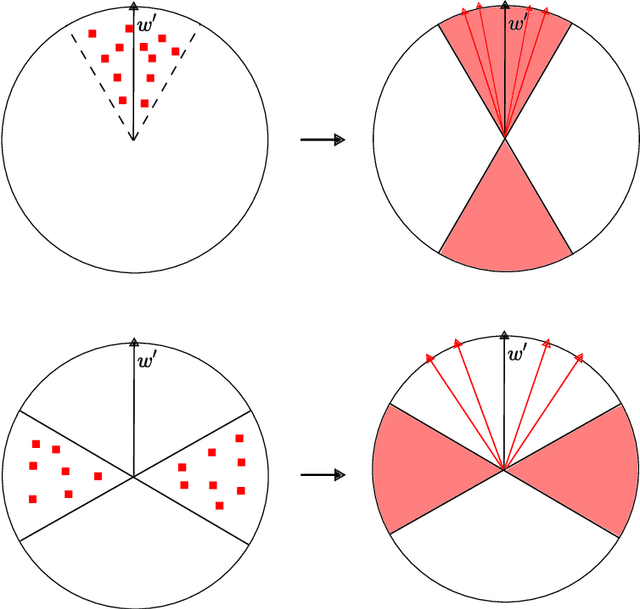
While supervised learning assumes the presence of labeled data, we may have prior information about how models should behave. In this paper, we formalize this notion as learning from explanation constraints and provide a learning theoretic framework to analyze how such explanations can improve the learning of our models. For what models would explanations be helpful? Our first key contribution addresses this question via the definition of what we call EPAC models (models that satisfy these constraints in expectation over new data), and we analyze this class of models using standard learning theoretic tools. Our second key contribution is to characterize these restrictions (in terms of their Rademacher complexities) for a canonical class of explanations given by gradient information for linear models and two layer neural networks. Finally, we provide an algorithmic solution for our framework, via a variational approximation that achieves better performance and satisfies these constraints more frequently, when compared to simpler augmented Lagrangian methods to incorporate these explanations. We demonstrate the benefits of our approach over a large array of synthetic and real-world experiments.