 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Specific Knowledge Summarization with Entity Evolutionary Networks
Sep 29, 2019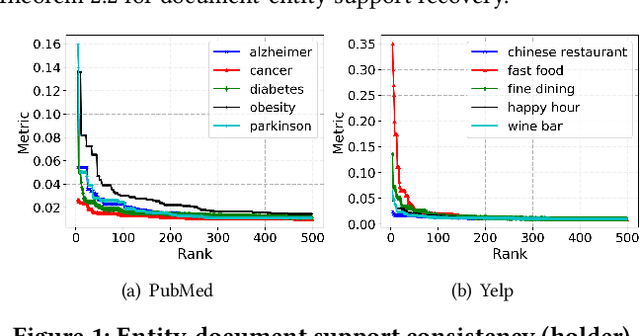
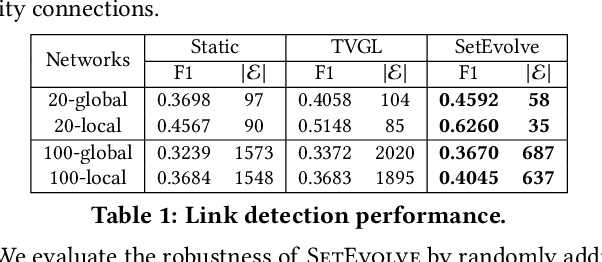
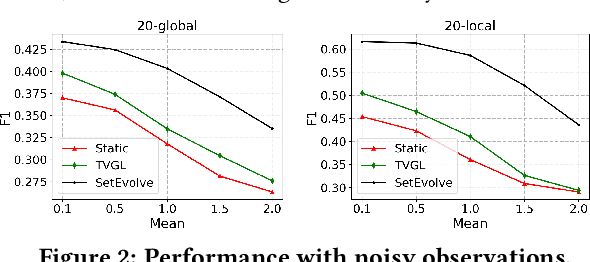
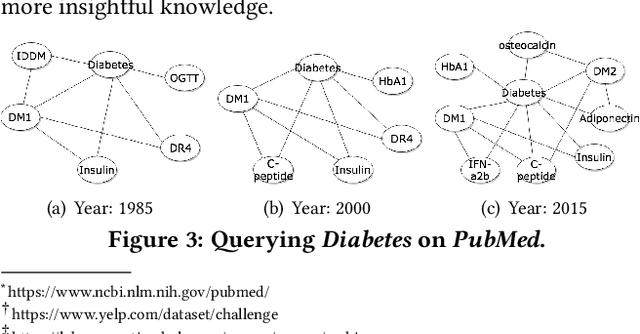
Given a query, unlike traditional IR that finds relevant documents or entities, in this work, we focus on retrieving both entities and their connections for insightful knowledge summarization. For example, given a query "computer vision" on a CS literature corpus, rather than returning a list of relevant entities like "cnn", "imagenet" and "svm", we are interested in the connections among them, and furthermore, the evolution patterns of such connections along particular ordinal dimensions such as time. Particularly, we hope to provide structural knowledge relevant to the query, such as "svm" is related to "imagenet" but not "cnn". Moreover, we aim to model the changing trends of the connections, such as "cnn" becomes highly related to "imagenet" after 2010, which enables the tracking of knowledge evolutions. In this work, to facilitate such a novel insightful search system, we propose \textsc{SetEvolve}, which is a unified framework based on nonparanomal graphical models for evolutionary network construction from large text corpora. Systematic experiments on synthetic data and insightful case studies on real-world corpora demonstrate the utility of \textsc{SetEvolve}.
Bayesian Regularization for Graphical Models with Unequal Shrinkage
May 20, 2018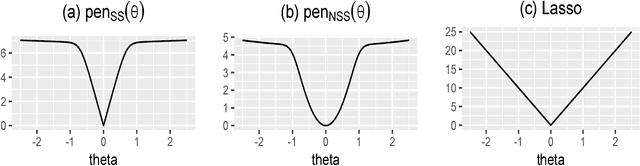

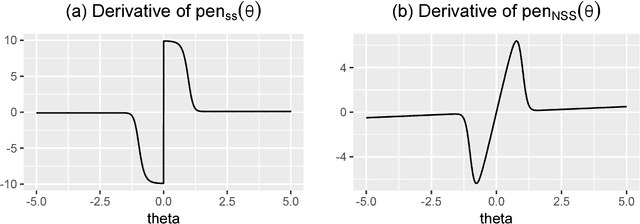
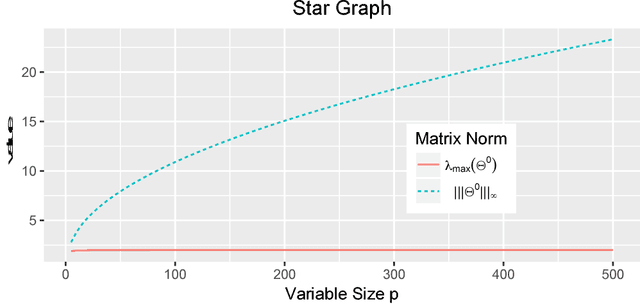
We consider a Bayesian framework for estimating a high-dimensional sparse precision matrix, in which adaptive shrinkage and sparsity are induced by a mixture of Laplace priors. Besides discussing our formulation from the Bayesian standpoint, we investigate the MAP (maximum a posteriori) estimator from a penalized likelihood perspective that gives rise to a new non-convex penalty approximating the $\ell_0$ penalty. Optimal error rates for estimation consistency in terms of various matrix norms along with selection consistency for sparse structure recovery are shown for the unique MAP estimator under mild conditions. For fast and efficient computation, an EM algorithm is proposed to compute the MAP estimator of the precision matrix and (approximate) posterior probabilities on the edges of the underlying sparse structure. Through extensive simulation studies and a real application to a call center data, we have demonstrated the fine performance of our method compared with existing alternatives.