 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMere Contrastive Learning for Cross-Domain Sentiment Analysis
Paper and Code


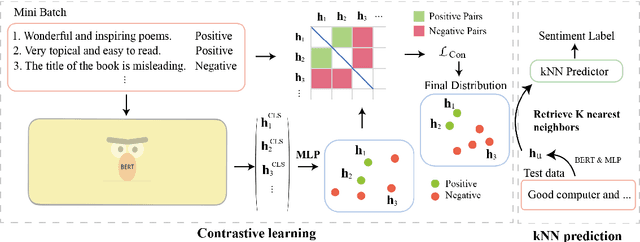

Cross-domain sentiment analysis aims to predict the sentiment of texts in the target domain using the model trained on the source domain to cope with the scarcity of labeled data. Previous studies are mostly cross-entropy-based methods for the task, which suffer from instability and poor generalization. In this paper, we explore contrastive learning on the cross-domain sentiment analysis task. We propose a modified contrastive objective with in-batch negative samples so that the sentence representations from the same class will be pushed close while those from the different classes become further apart in the latent space. Experiments on two widely used datasets show that our model can achieve state-of-the-art performance in both cross-domain and multi-domain sentiment analysis tasks. Meanwhile, visualizations demonstrate the effectiveness of transferring knowledge learned in the source domain to the target domain and the adversarial test verifies the robustness of our model.