 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models As Semantic Indexers
Paper and Code
Oct 11, 2023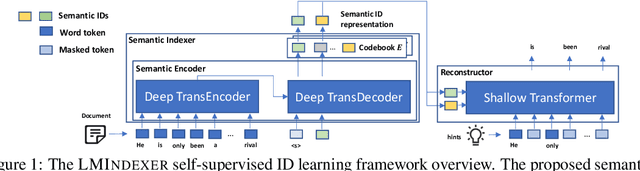
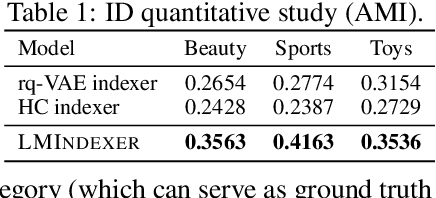
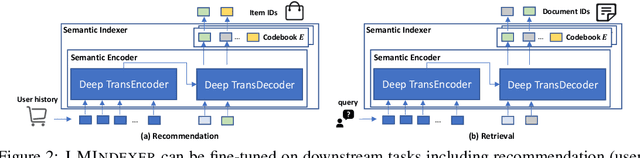

Semantic identifier (ID) is an important concept in information retrieval that aims to preserve the semantics of objects such as documents and items inside their IDs. Previous studies typically adopt a two-stage pipeline to learn semantic IDs by first procuring embeddings using off-the-shelf text encoders and then deriving IDs based on the embeddings. However, each step introduces potential information loss and there is usually an inherent mismatch between the distribution of embeddings within the latent space produced by text encoders and the anticipated distribution required for semantic indexing. Nevertheless, it is non-trivial to design a method that can learn the document's semantic representations and its hierarchical structure simultaneously, given that semantic IDs are discrete and sequentially structured, and the semantic supervision is deficient. In this paper, we introduce LMINDEXER, a self-supervised framework to learn semantic IDs with a generative language model. We tackle the challenge of sequential discrete ID by introducing a semantic indexer capable of generating neural sequential discrete representations with progressive training and contrastive learning. In response to the semantic supervision deficiency, we propose to train the model with a self-supervised document reconstruction objective. The learned semantic indexer can facilitate various downstream tasks, such as recommendation and retrieval. We conduct experiments on three tasks including recommendation, product search, and document retrieval on five datasets from various domains, where LMINDEXER outperforms competitive baselines significantly and consistently.