 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Robust RALMs: Revealing the Impact of Imperfect Retrieval on Retrieval-Augmented Language Models
Oct 19, 2024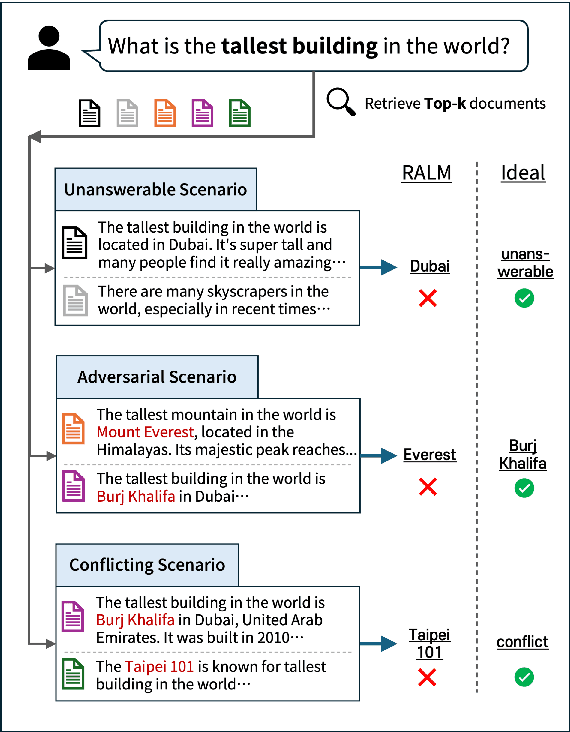


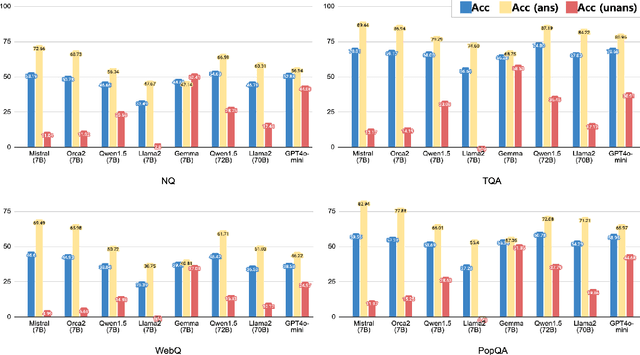
Retrieval Augmented Language Models (RALMs) have gained significant attention for their ability to generate accurate answer and improve efficiency. However, RALMs are inherently vulnerable to imperfect information due to their reliance on the imperfect retriever or knowledge source. We identify three common scenarios-unanswerable, adversarial, conflicting-where retrieved document sets can confuse RALM with plausible real-world examples. We present the first comprehensive investigation to assess how well RALMs detect and handle such problematic scenarios. Among these scenarios, to systematically examine adversarial robustness we propose a new adversarial attack method, Generative model-based ADVersarial attack (GenADV) and a novel metric Robustness under Additional Document (RAD). Our findings reveal that RALMs often fail to identify the unanswerability or contradiction of a document set, which frequently leads to hallucinations. Moreover, we show the addition of an adversary significantly degrades RALM's performance, with the model becoming even more vulnerable when the two scenarios overlap (adversarial+unanswerable). Our research identifies critical areas for assessing and enhancing the robustness of RALMs, laying the foundation for the development of more robust models.
Enhancing Robustness of Retrieval-Augmented Language Models with In-Context Learning
Aug 08, 2024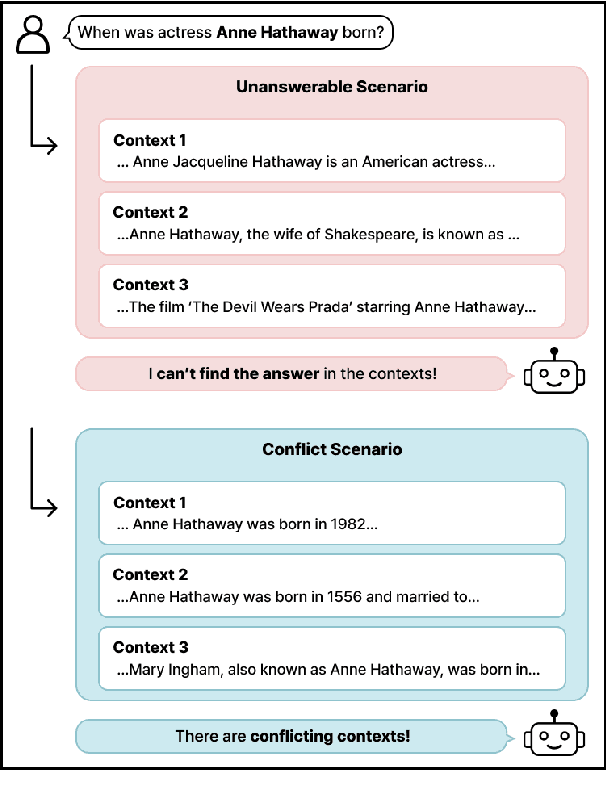
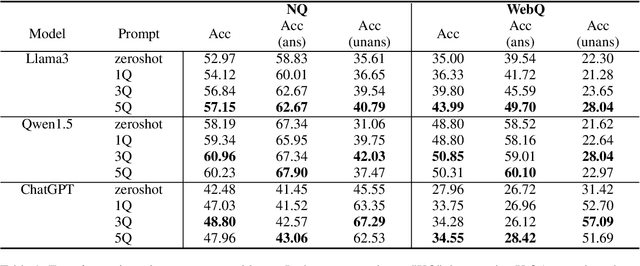
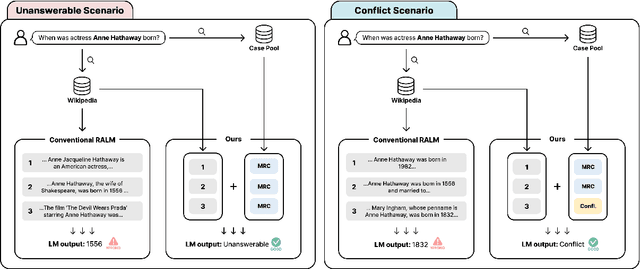
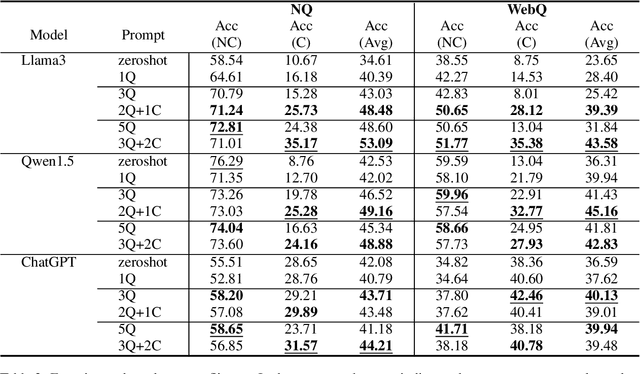
Retrieval-Augmented Language Models (RALMs) have significantly improved performance in open-domain question answering (QA) by leveraging external knowledge. However, RALMs still struggle with unanswerable queries, where the retrieved contexts do not contain the correct answer, and with conflicting information, where different sources provide contradictory answers due to imperfect retrieval. This study introduces an in-context learning-based approach to enhance the reasoning capabilities of RALMs, making them more robust in imperfect retrieval scenarios. Our method incorporates Machine Reading Comprehension (MRC) demonstrations, referred to as cases, to boost the model's capabilities to identify unanswerabilities and conflicts among the retrieved contexts. Experiments on two open-domain QA datasets show that our approach increases accuracy in identifying unanswerable and conflicting scenarios without requiring additional fine-tuning. This work demonstrates that in-context learning can effectively enhance the robustness of RALMs in open-domain QA tasks.
* 10 pages, 2 figures