 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntGrad MT: Eliciting LLMs' Machine Translation Capabilities with Sentence Interpolation and Gradual MT
Oct 15, 2024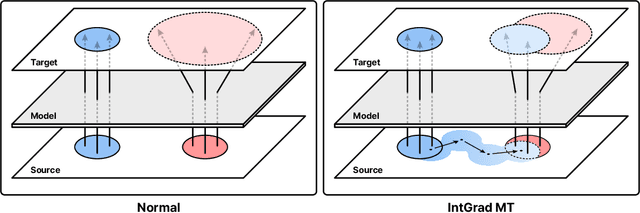
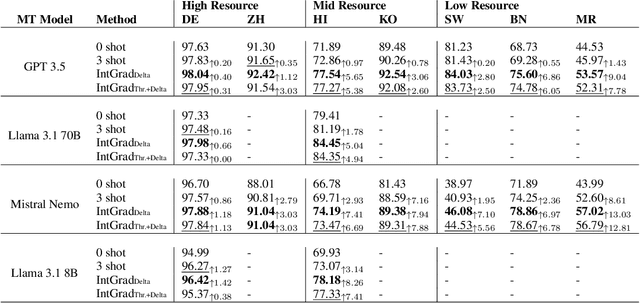
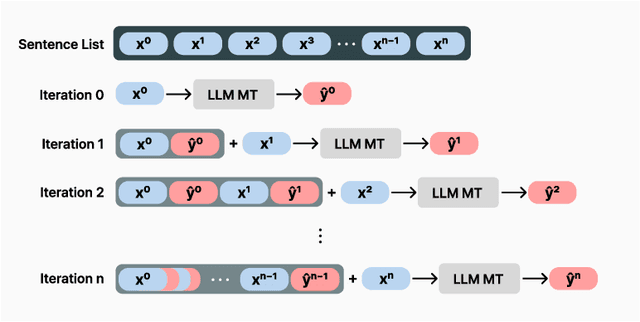

Recent Large Language Models (LLMs) have demonstrated strong performance in translation without needing to be finetuned on additional parallel corpora. However, they still underperform for low-resource language pairs. Previous works have focused on mitigating this issue by leveraging relevant few-shot examples or external resources such as dictionaries or grammar books, making models heavily reliant on these nonparametric sources of information. In this paper, we propose a novel method named IntGrad MT that focuses on fully exploiting an LLM's inherent translation capability. IntGrad MT achieves this by constructing a chain of few-shot examples, each consisting of a source sentence and the model's own translation, that rise incrementally in difficulty. IntGrad MT employs two techniques: Sentence Interpolation, which generates a sequence of sentences that gradually change from an easy sentence to translate to a difficult one, and Gradual MT, which sequentially translates this chain using translations of earlier sentences as few-shot examples for the translation of subsequent ones. With this approach, we observe a substantial enhancement in the xCOMET scores of various LLMs for multiple languages, especially in low-resource languages such as Hindi(8.26), Swahili(7.10), Bengali(6.97) and Marathi(13.03). Our approach presents a practical way of enhancing LLMs' performance without extra training.
Enhancing Robustness of Retrieval-Augmented Language Models with In-Context Learning
Aug 08, 2024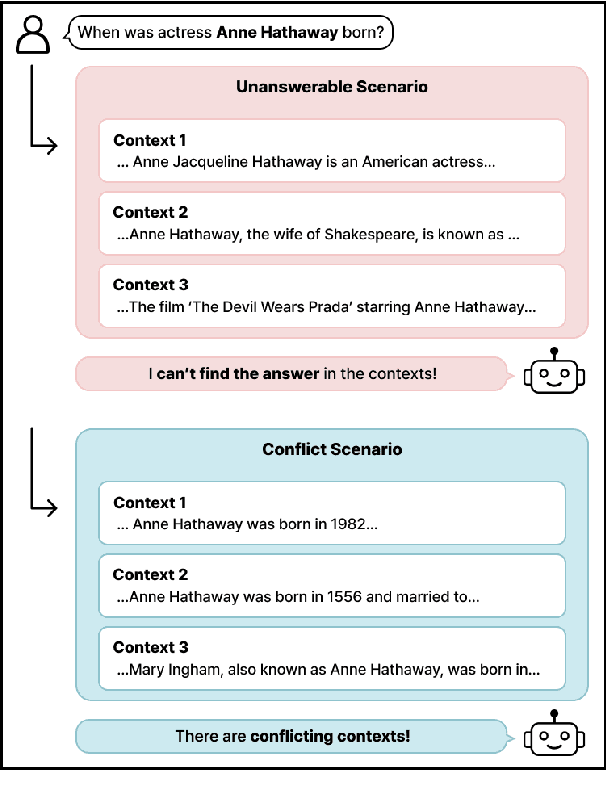
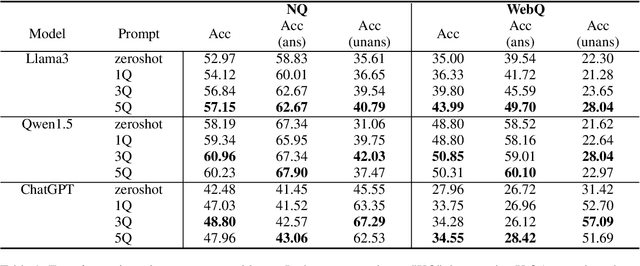
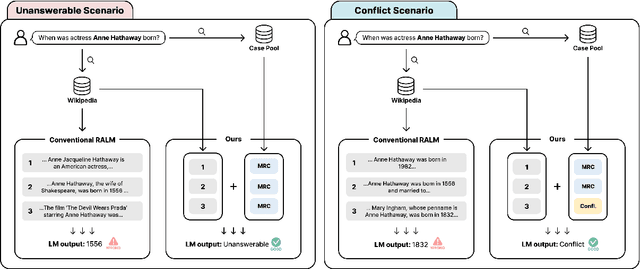
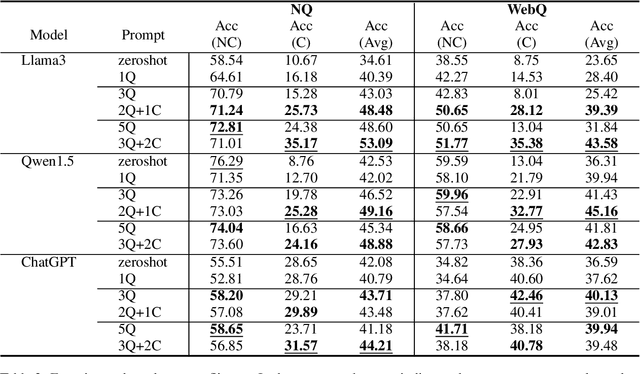
Retrieval-Augmented Language Models (RALMs) have significantly improved performance in open-domain question answering (QA) by leveraging external knowledge. However, RALMs still struggle with unanswerable queries, where the retrieved contexts do not contain the correct answer, and with conflicting information, where different sources provide contradictory answers due to imperfect retrieval. This study introduces an in-context learning-based approach to enhance the reasoning capabilities of RALMs, making them more robust in imperfect retrieval scenarios. Our method incorporates Machine Reading Comprehension (MRC) demonstrations, referred to as cases, to boost the model's capabilities to identify unanswerabilities and conflicts among the retrieved contexts. Experiments on two open-domain QA datasets show that our approach increases accuracy in identifying unanswerable and conflicting scenarios without requiring additional fine-tuning. This work demonstrates that in-context learning can effectively enhance the robustness of RALMs in open-domain QA tasks.
* 10 pages, 2 figures