 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe CoR: A Dual-Expert Approach to Integrating Imitation Learning and Safe Reinforcement Learning Using Constraint Rewards
Jul 02, 2024
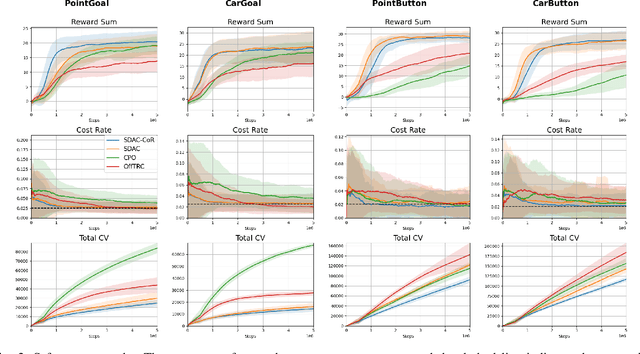


In the realm of autonomous agents, ensuring safety and reliability in complex and dynamic environments remains a paramount challenge. Safe reinforcement learning addresses these concerns by introducing safety constraints, but still faces challenges in navigating intricate environments such as complex driving situations. To overcome these challenges, we present the safe constraint reward (Safe CoR) framework, a novel method that utilizes two types of expert demonstrations$\unicode{x2013}$reward expert demonstrations focusing on performance optimization and safe expert demonstrations prioritizing safety. By exploiting a constraint reward (CoR), our framework guides the agent to balance performance goals of reward sum with safety constraints. We test the proposed framework in diverse environments, including the safety gym, metadrive, and the real$\unicode{x2013}$world Jackal platform. Our proposed framework enhances the performance of algorithms by $39\%$ and reduces constraint violations by $88\%$ on the real-world Jackal platform, demonstrating the framework's efficacy. Through this innovative approach, we expect significant advancements in real-world performance, leading to transformative effects in the realm of safe and reliable autonomous agents.
Boosting Graph Neural Networks by Injecting Pooling in Message Passing
Feb 08, 2022There has been tremendous success in the field of graph neural networks (GNNs) as a result of the development of the message-passing (MP) layer, which updates the representation of a node by combining it with its neighbors to address variable-size and unordered graphs. Despite the fruitful progress of MP GNNs, their performance can suffer from over-smoothing, when node representations become too similar and even indistinguishable from one another. Furthermore, it has been reported that intrinsic graph structures are smoothed out as the GNN layer increases. Inspired by the edge-preserving bilateral filters used in image processing, we propose a new, adaptable, and powerful MP framework to prevent over-smoothing. Our bilateral-MP estimates a pairwise modular gradient by utilizing the class information of nodes, and further preserves the global graph structure by using the gradient when the aggregating function is applied. Our proposed scheme can be generalized to all ordinary MP GNNs. Experiments on five medium-size benchmark datasets using four state-of-the-art MP GNNs indicate that the bilateral-MP improves performance by alleviating over-smoothing. By inspecting quantitative measurements, we additionally validate the effectiveness of the proposed mechanism in preventing the over-smoothing issue.