 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe CoR: A Dual-Expert Approach to Integrating Imitation Learning and Safe Reinforcement Learning Using Constraint Rewards
Paper and Code
Jul 02, 2024
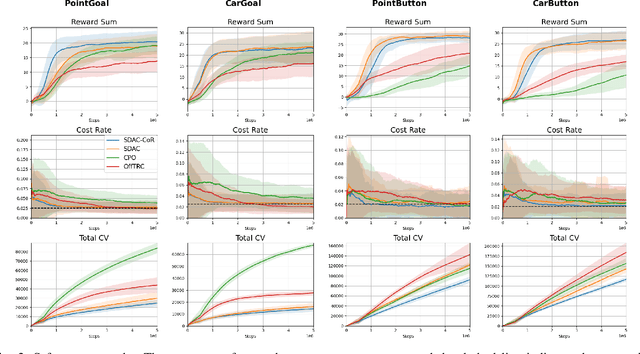


In the realm of autonomous agents, ensuring safety and reliability in complex and dynamic environments remains a paramount challenge. Safe reinforcement learning addresses these concerns by introducing safety constraints, but still faces challenges in navigating intricate environments such as complex driving situations. To overcome these challenges, we present the safe constraint reward (Safe CoR) framework, a novel method that utilizes two types of expert demonstrations$\unicode{x2013}$reward expert demonstrations focusing on performance optimization and safe expert demonstrations prioritizing safety. By exploiting a constraint reward (CoR), our framework guides the agent to balance performance goals of reward sum with safety constraints. We test the proposed framework in diverse environments, including the safety gym, metadrive, and the real$\unicode{x2013}$world Jackal platform. Our proposed framework enhances the performance of algorithms by $39\%$ and reduces constraint violations by $88\%$ on the real-world Jackal platform, demonstrating the framework's efficacy. Through this innovative approach, we expect significant advancements in real-world performance, leading to transformative effects in the realm of safe and reliable autonomous agents.