 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsallis Reinforcement Learning: A Unified Framework for Maximum Entropy Reinforcement Learning
Paper and Code
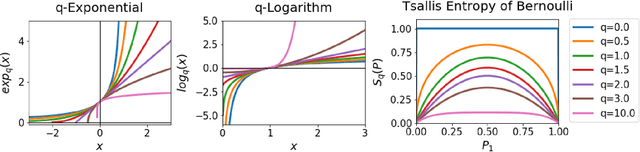

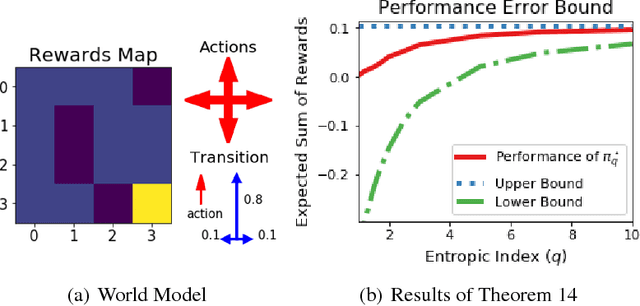
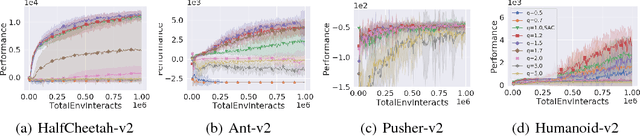
In this paper, we present a new class of Markov decision processes (MDPs), called Tsallis MDPs, with Tsallis entropy maximization, which generalizes existing maximum entropy reinforcement learning (RL). A Tsallis MDP provides a unified framework for the original RL problem and RL with various types of entropy, including the well-known standard Shannon-Gibbs (SG) entropy, using an additional real-valued parameter, called an entropic index. By controlling the entropic index, we can generate various types of entropy, including the SG entropy, and a different entropy results in a different class of the optimal policy in Tsallis MDPs. We also provide a full mathematical analysis of Tsallis MDPs, including the optimality condition, performance error bounds, and convergence. Our theoretical result enables us to use any positive entropic index in RL. To handle complex and large-scale problems, we propose a model-free actor-critic RL method using Tsallis entropy maximization. We evaluate the regularization effect of the Tsallis entropy with various values of entropic indices and show that the entropic index controls the exploration tendency of the proposed method. For a different type of RL problems, we find that a different value of the entropic index is desirable. The proposed method is evaluated using the MuJoCo simulator and achieves the state-of-the-art performance.