 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Efficient Patch-based Training for INR-based GANs
Jul 09, 2022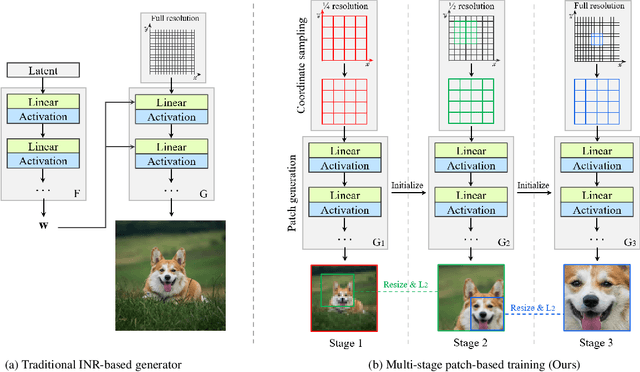
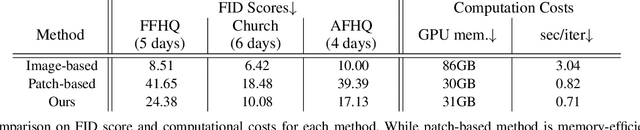


Recent studies have shown remarkable progress in GANs based on implicit neural representation (INR) - an MLP that produces an RGB value given its (x, y) coordinate. They represent an image as a continuous version of the underlying 2D signal instead of a 2D array of pixels, which opens new horizons for GAN applications (e.g., zero-shot super-resolution, image outpainting). However, training existing approaches require a heavy computational cost proportional to the image resolution, since they compute an MLP operation for every (x, y) coordinate. To alleviate this issue, we propose a multi-stage patch-based training, a novel and scalable approach that can train INR-based GANs with a flexible computational cost regardless of the image resolution. Specifically, our method allows to generate and discriminate by patch to learn the local details of the image and learn global structural information by a novel reconstruction loss to enable efficient GAN training. We conduct experiments on several benchmark datasets to demonstrate that our approach enhances baseline models in GPU memory while maintaining FIDs at a reasonable level.