 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRising Multi-Armed Bandits with Known Horizons
Feb 13, 2026The Rising Multi-Armed Bandit (RMAB) framework models environments where expected rewards of arms increase with plays, which models practical scenarios where performance of each option improves with the repeated usage, such as in robotics and hyperparameter tuning. For instance, in hyperparameter tuning, the validation accuracy of a model configuration (arm) typically increases with each training epoch. A defining characteristic of RMAB is em horizon-dependent optimality: unlike standard settings, the optimal strategy here shifts dramatically depending on the available budget $T$. This implies that knowledge of $T$ yields significantly greater utility in RMAB, empowering the learner to align its decision-making with this shifting optimality. However, the horizon-aware setting remains underexplored. To address this, we propose a novel CUmulative Reward Estimation UCB (CURE-UCB) that explicitly integrates the horizon. We provide a rigorous analysis establishing a new regret upper bound and prove that our method strictly outperforms horizon-agnostic strategies in structured environments like ``linear-then-flat'' instances. Extensive experiments demonstrate its significant superiority over baselines.
Don't Just Follow MLLM Plans: Robust and Efficient Planning for Open-world Agents
May 30, 2025



Developing autonomous agents capable of mastering complex, multi-step tasks in unpredictable, interactive environments presents a significant challenge. While Large Language Models (LLMs) offer promise for planning, existing approaches often rely on problematic internal knowledge or make unrealistic environmental assumptions. Although recent work explores learning planning knowledge, they still retain limitations due to partial reliance on external knowledge or impractical setups. Indeed, prior research has largely overlooked developing agents capable of acquiring planning knowledge from scratch, directly in realistic settings. While realizing this capability is necessary, it presents significant challenges, primarily achieving robustness given the substantial risk of incorporating LLMs' inaccurate knowledge. Moreover, efficiency is crucial for practicality as learning can demand prohibitive exploration. In response, we introduce Robust and Efficient Planning for Open-world Agents (REPOA), a novel framework designed to tackle these issues. REPOA features three key components: adaptive dependency learning and fine-grained failure-aware operation memory to enhance robustness to knowledge inaccuracies, and difficulty-based exploration to improve learning efficiency. Our evaluation in two established open-world testbeds demonstrates REPOA's robust and efficient planning, showcasing its capability to successfully obtain challenging late-game items that were beyond the reach of prior approaches.
Combinatorial Rising Bandit
Dec 01, 2024



Combinatorial online learning is a fundamental task to decide the optimal combination of base arms in sequential interactions with systems providing uncertain rewards, which is applicable to diverse domains such as robotics, social advertising, network routing and recommendation systems. In real-world scenarios, we often observe rising rewards, where the selection of a base arm not only provides an instantaneous reward but also contributes to the enhancement of future rewards, {\it e.g.}, robots enhancing proficiency through practice and social influence strengthening in the history of successful recommendations. To address this, we introduce the problem of combinatorial rising bandit to minimize policy regret and propose a provably efficient algorithm, called Combinatorial Rising Upper Confidence Bound (CRUCB), of which regret upper bound is close to a regret lower bound. To the best of our knowledge, previous studies do not provide a sub-linear regret lower bound, making it impossible to assess the efficiency of their algorithms. However, we provide the sub-linear regret lower bound for combinatorial rising bandit and show that CRUCB is provably efficient by showing that the regret upper bound is close to the regret lower bound. In addition, we empirically demonstrate the effectiveness and superiority of CRUCB not only in synthetic environments but also in realistic applications of deep reinforcement learning.
Few-Shot Unlearning by Model Inversion
May 31, 2022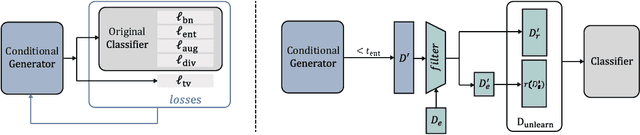

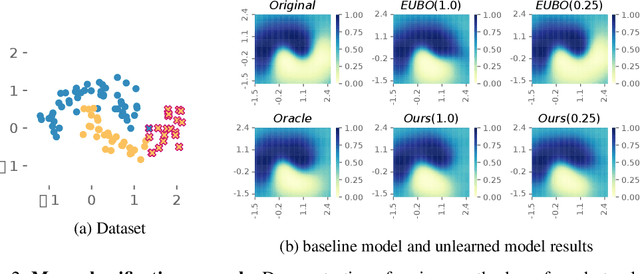
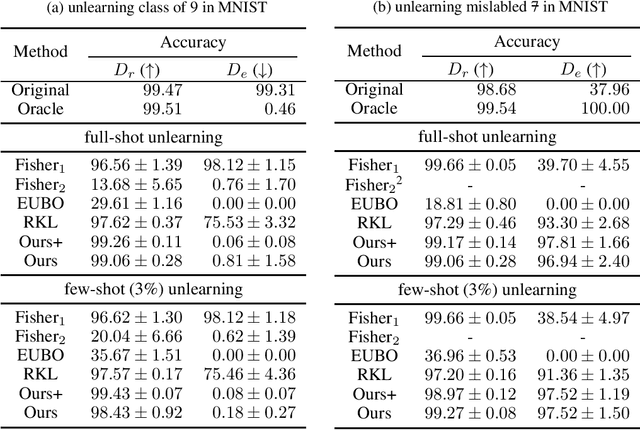
We consider the problem of machine unlearning to erase a target dataset, which causes an unwanted behavior, from the trained model when the training dataset is not given. Previous works have assumed that the target dataset indicates all the training data imposing the unwanted behavior. However, it is often infeasible to obtain such a complete indication. We hence address a practical scenario of unlearning provided a few samples of target data, so-called few-shot unlearning. To this end, we devise a straightforward framework, including a new model inversion technique to retrieve the training data from the model, followed by filtering out samples similar to the target samples and then relearning. We demonstrate that our method using only a subset of target data can outperform the state-of-the-art methods with a full indication of target data.