 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Generation with Estimation of Source Reliability
Paper and Code
Oct 30, 2024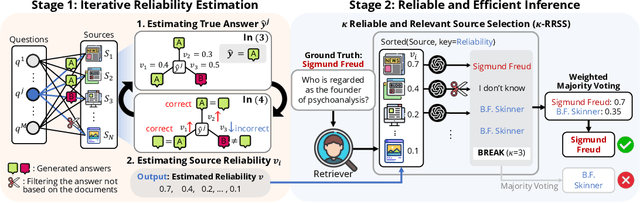
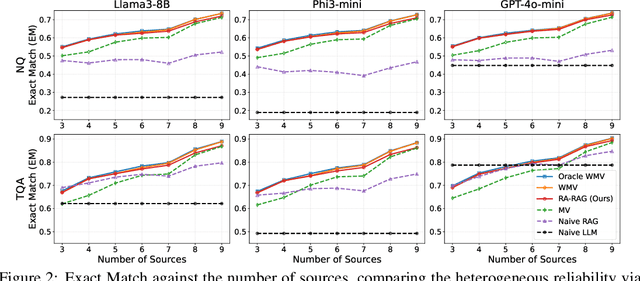

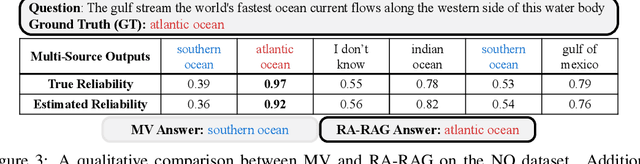
Retrieval-augmented generation (RAG) addresses key limitations of large language models (LLMs), such as hallucinations and outdated knowledge, by incorporating external databases. These databases typically consult multiple sources to encompass up-to-date and various information. However, standard RAG methods often overlook the heterogeneous source reliability in the multi-source database and retrieve documents solely based on relevance, making them prone to propagating misinformation. To address this, we propose Reliability-Aware RAG (RA-RAG) which estimates the reliability of multiple sources and incorporates this information into both retrieval and aggregation processes. Specifically, it iteratively estimates source reliability and true answers for a set of queries with no labelling. Then, it selectively retrieves relevant documents from a few of reliable sources and aggregates them using weighted majority voting, where the selective retrieval ensures scalability while not compromising the performance. We also introduce a benchmark designed to reflect real-world scenarios with heterogeneous source reliability and demonstrate the effectiveness of RA-RAG compared to a set of baselines.