 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFulfilling Formal Specifications ASAP by Model-free Reinforcement Learning
Paper and Code
Apr 25, 2023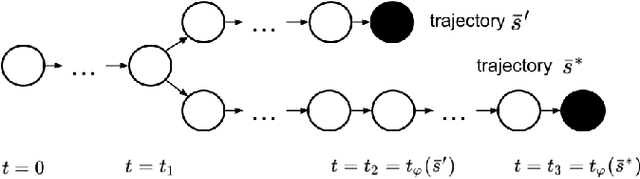
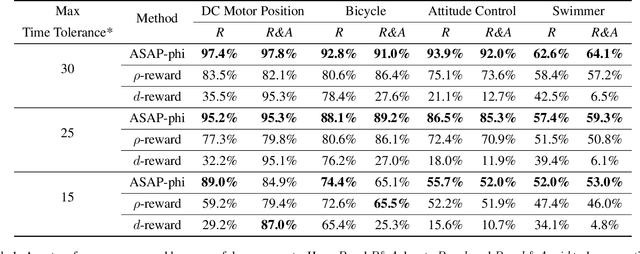
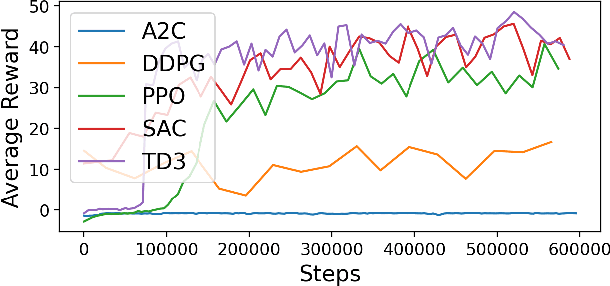
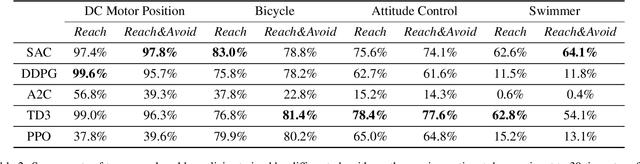
We propose a model-free reinforcement learning solution, namely the ASAP-Phi framework, to encourage an agent to fulfill a formal specification ASAP. The framework leverages a piece-wise reward function that assigns quantitative semantic reward to traces not satisfying the specification, and a high constant reward to the remaining. Then, it trains an agent with an actor-critic-based algorithm, such as soft actor-critic (SAC), or deep deterministic policy gradient (DDPG). Moreover, we prove that ASAP-Phi produces policies that prioritize fulfilling a specification ASAP. Extensive experiments are run, including ablation studies, on state-of-the-art benchmarks. Results show that our framework succeeds in finding sufficiently fast trajectories for up to 97\% test cases and defeats baselines.