 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIBCL: Zero-shot Model Generation for Task Trade-offs in Continual Learning
Oct 09, 2023Like generic multi-task learning, continual learning has the nature of multi-objective optimization, and therefore faces a trade-off between the performance of different tasks. That is, to optimize for the current task distribution, it may need to compromise performance on some previous tasks. This means that there exist multiple models that are Pareto-optimal at different times, each addressing a distinct task performance trade-off. Researchers have discussed how to train particular models to address specific trade-off preferences. However, existing algorithms require training overheads proportional to the number of preferences -- a large burden when there are multiple, possibly infinitely many, preferences. As a response, we propose Imprecise Bayesian Continual Learning (IBCL). Upon a new task, IBCL (1) updates a knowledge base in the form of a convex hull of model parameter distributions and (2) obtains particular models to address task trade-off preferences with zero-shot. That is, IBCL does not require any additional training overhead to generate preference-addressing models from its knowledge base. We show that models obtained by IBCL have guarantees in identifying the Pareto optimal parameters. Moreover, experiments on standard image classification and NLP tasks support this guarantee. Statistically, IBCL improves average per-task accuracy by at most 23\% and peak per-task accuracy by at most 15\% with respect to the baseline methods, with steadily near-zero or positive backward transfer. Most importantly, IBCL significantly reduces the training overhead from training 1 model per preference to at most 3 models for all preferences.
Zero-shot Task Preference Addressing Enabled by Imprecise Bayesian Continual Learning
May 24, 2023Like generic multi-task learning, continual learning has the nature of multi-objective optimization, and therefore faces a trade-off between the performance of different tasks. That is, to optimize for the current task distribution, it may need to compromise performance on some tasks to improve on others. This means there exist multiple models that are each optimal at different times, each addressing a distinct task-performance trade-off. Researchers have discussed how to train particular models to address specific preferences on these trade-offs. However, existing algorithms require additional sample overheads -- a large burden when there are multiple, possibly infinitely many, preferences. As a response, we propose Imprecise Bayesian Continual Learning (IBCL). Upon a new task, IBCL (1) updates a knowledge base in the form of a convex hull of model parameter distributions and (2) obtains particular models to address preferences with zero-shot. That is, IBCL does not require any additional training overhead to construct preference-addressing models from its knowledge base. We show that models obtained by IBCL have guarantees in identifying the preferred parameters. Moreover, experiments show that IBCL is able to locate the Pareto set of parameters given a preference, maintain similar to better performance than baseline methods, and significantly reduce training overhead via zero-shot preference addressing.
Causal Repair of Learning-enabled Cyber-physical Systems
Apr 26, 2023Models of actual causality leverage domain knowledge to generate convincing diagnoses of events that caused an outcome. It is promising to apply these models to diagnose and repair run-time property violations in cyber-physical systems (CPS) with learning-enabled components (LEC). However, given the high diversity and complexity of LECs, it is challenging to encode domain knowledge (e.g., the CPS dynamics) in a scalable actual causality model that could generate useful repair suggestions. In this paper, we focus causal diagnosis on the input/output behaviors of LECs. Specifically, we aim to identify which subset of I/O behaviors of the LEC is an actual cause for a property violation. An important by-product is a counterfactual version of the LEC that repairs the run-time property by fixing the identified problematic behaviors. Based on this insights, we design a two-step diagnostic pipeline: (1) construct and Halpern-Pearl causality model that reflects the dependency of property outcome on the component's I/O behaviors, and (2) perform a search for an actual cause and corresponding repair on the model. We prove that our pipeline has the following guarantee: if an actual cause is found, the system is guaranteed to be repaired; otherwise, we have high probabilistic confidence that the LEC under analysis did not cause the property violation. We demonstrate that our approach successfully repairs learned controllers on a standard OpenAI Gym benchmark.
Fulfilling Formal Specifications ASAP by Model-free Reinforcement Learning
Apr 25, 2023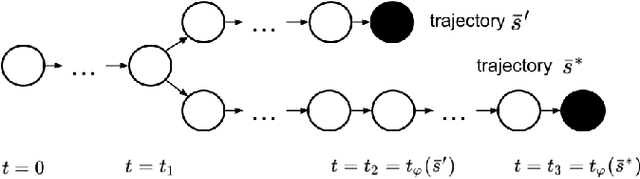
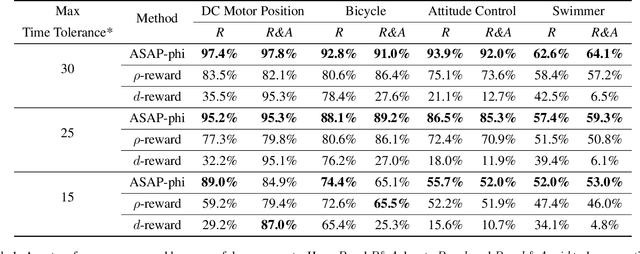
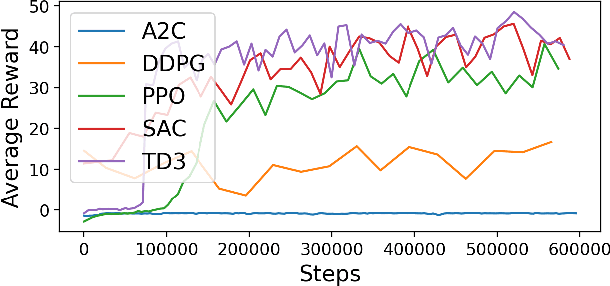
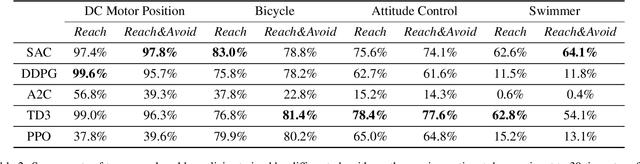
We propose a model-free reinforcement learning solution, namely the ASAP-Phi framework, to encourage an agent to fulfill a formal specification ASAP. The framework leverages a piece-wise reward function that assigns quantitative semantic reward to traces not satisfying the specification, and a high constant reward to the remaining. Then, it trains an agent with an actor-critic-based algorithm, such as soft actor-critic (SAC), or deep deterministic policy gradient (DDPG). Moreover, we prove that ASAP-Phi produces policies that prioritize fulfilling a specification ASAP. Extensive experiments are run, including ablation studies, on state-of-the-art benchmarks. Results show that our framework succeeds in finding sufficiently fast trajectories for up to 97\% test cases and defeats baselines.
Confidence Composition for Monitors of Verification Assumptions
Nov 03, 2021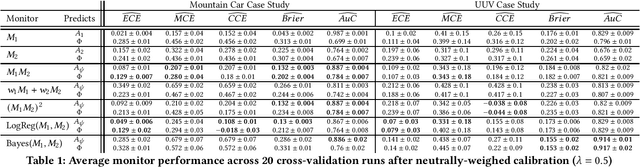

Closed-loop verification of cyber-physical systems with neural network controllers offers strong safety guarantees under certain assumptions. It is, however, difficult to determine whether these guarantees apply at run time because verification assumptions may be violated. To predict safety violations in a verified system, we propose a three-step framework for monitoring the confidence in verification assumptions. First, we represent the sufficient condition for verified safety with a propositional logical formula over assumptions. Second, we build calibrated confidence monitors that evaluate the probability that each assumption holds. Third, we obtain the confidence in the verification guarantees by composing the assumption monitors using a composition function suitable for the logical formula. Our framework provides theoretical bounds on the calibration and conservatism of compositional monitors. In two case studies, we demonstrate that the composed monitors improve over their constituents and successfully predict safety violations.