Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Language Models Benefit from Public Pre-training
Paper and Code
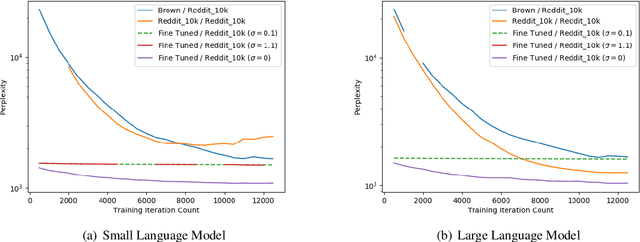


Language modeling is a keystone task in natural language processing. When training a language model on sensitive information, differential privacy (DP) allows us to quantify the degree to which our private data is protected. However, training algorithms which enforce differential privacy often lead to degradation in model quality. We study the feasibility of learning a language model which is simultaneously high-quality and privacy preserving by tuning a public base model on a private corpus. We find that DP fine-tuning boosts the performance of language models in the private domain, making the training of such models possible.
View paper on