 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Analysis of NLP Models is Manipulable
Paper and Code


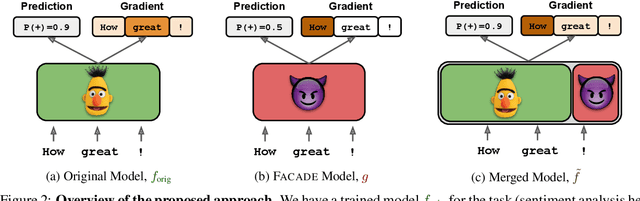
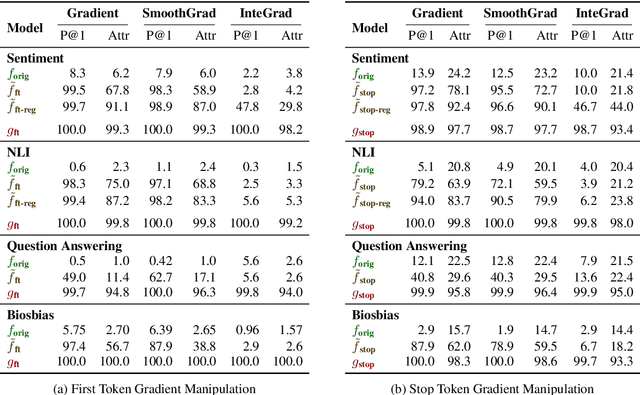
Gradient-based analysis methods, such as saliency map visualizations and adversarial input perturbations, have found widespread use in interpreting neural NLP models due to their simplicity, flexibility, and most importantly, their faithfulness. In this paper, however, we demonstrate that the gradients of a model are easily manipulable, and thus bring into question the reliability of gradient-based analyses. In particular, we merge the layers of a target model with a Facade that overwhelms the gradients without affecting the predictions. This Facade can be trained to have gradients that are misleading and irrelevant to the task, such as focusing only on the stop words in the input. On a variety of NLP tasks (text classification, NLI, and QA), we show that our method can manipulate numerous gradient-based analysis techniques: saliency maps, input reduction, and adversarial perturbations all identify unimportant or targeted tokens as being highly important. The code and a tutorial of this paper is available at http://ucinlp.github.io/facade.