 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedMap: Iterative Magnitude-Based Pruning for Communication-Efficient Federated Learning
Jun 27, 2024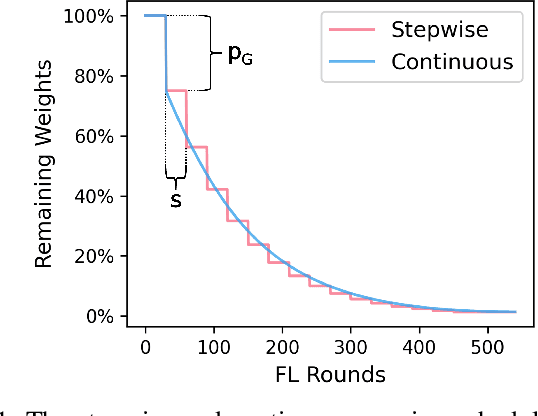
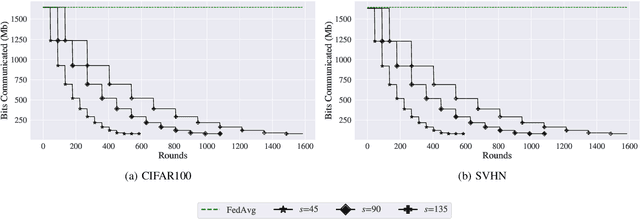
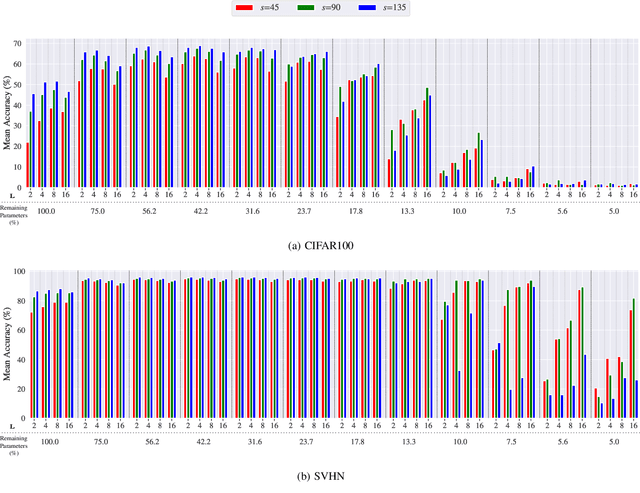
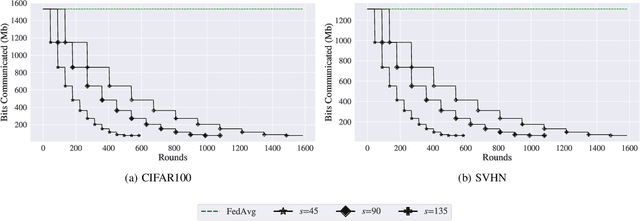
Federated Learning (FL) is a distributed machine learning approach that enables training on decentralized data while preserving privacy. However, FL systems often involve resource-constrained client devices with limited computational power, memory, storage, and bandwidth. This paper introduces FedMap, a novel method that aims to enhance the communication efficiency of FL deployments by collaboratively learning an increasingly sparse global model through iterative, unstructured pruning. Importantly, FedMap trains a global model from scratch, unlike other methods reported in the literature, making it ideal for privacy-critical use cases such as in the medical and finance domains, where suitable pre-training data is often limited. FedMap adapts iterative magnitude-based pruning to the FL setting, ensuring all clients prune and refine the same subset of the global model parameters, therefore gradually reducing the global model size and communication overhead. The iterative nature of FedMap, forming subsequent models as subsets of predecessors, avoids parameter reactivation issues seen in prior work, resulting in stable performance. In this paper we provide an extensive evaluation of FedMap across diverse settings, datasets, model architectures, and hyperparameters, assessing performance in both IID and non-IID environments. Comparative analysis against the baseline approach demonstrates FedMap's ability to achieve more stable client model performance. For IID scenarios, FedMap achieves over $90$\% pruning without significant performance degradation. In non-IID settings, it achieves at least $~80$\% pruning while maintaining accuracy. FedMap offers a promising solution to alleviate communication bottlenecks in FL systems while retaining model accuracy.