Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-SQL Calibration: No Need to Ask -- Just Rescale Model Probabilities
Paper and Code

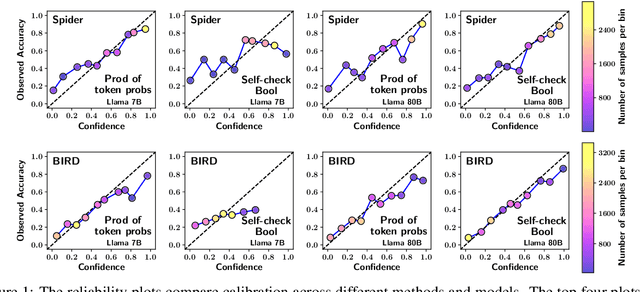

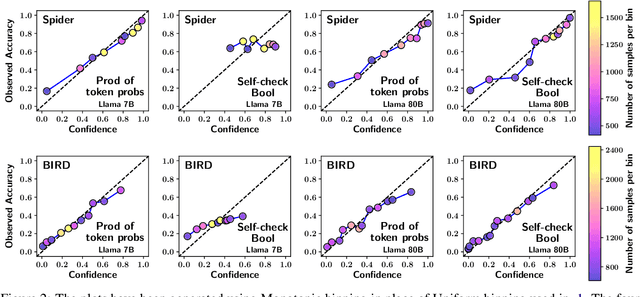
Calibration is crucial as large language models (LLMs) are increasingly deployed to convert natural language queries into SQL for commercial databases. In this work, we investigate calibration techniques for assigning confidence to generated SQL queries. We show that a straightforward baseline -- deriving confidence from the model's full-sequence probability -- outperforms recent methods that rely on follow-up prompts for self-checking and confidence verbalization. Our comprehensive evaluation, conducted across two widely-used Text-to-SQL benchmarks and multiple LLM architectures, provides valuable insights into the effectiveness of various calibration strategies.
View paper on