 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adversarial Attack Analysis on Malicious Advertisement URL Detection Framework
Paper and Code
Apr 27, 2022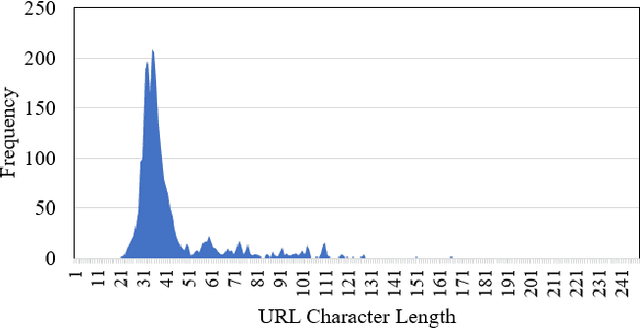
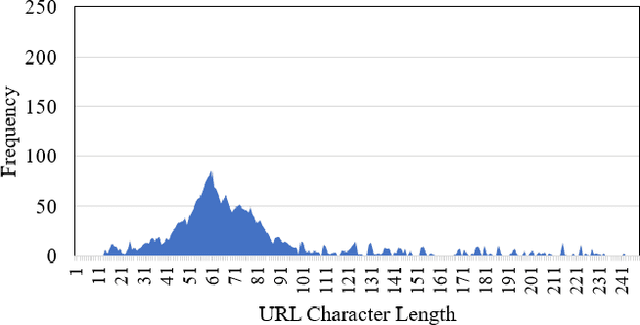
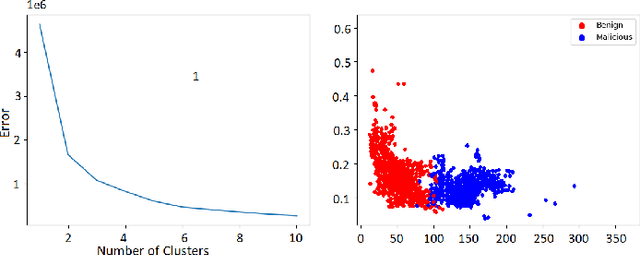
Malicious advertisement URLs pose a security risk since they are the source of cyber-attacks, and the need to address this issue is growing in both industry and academia. Generally, the attacker delivers an attack vector to the user by means of an email, an advertisement link or any other means of communication and directs them to a malicious website to steal sensitive information and to defraud them. Existing malicious URL detection techniques are limited and to handle unseen features as well as generalize to test data. In this study, we extract a novel set of lexical and web-scrapped features and employ machine learning technique to set up system for fraudulent advertisement URLs detection. The combination set of six different kinds of features precisely overcome the obfuscation in fraudulent URL classification. Based on different statistical properties, we use twelve different formatted datasets for detection, prediction and classification task. We extend our prediction analysis for mismatched and unlabelled datasets. For this framework, we analyze the performance of four machine learning techniques: Random Forest, Gradient Boost, XGBoost and AdaBoost in the detection part. With our proposed method, we can achieve a false negative rate as low as 0.0037 while maintaining high accuracy of 99.63%. Moreover, we devise a novel unsupervised technique for data clustering using K- Means algorithm for the visual analysis. This paper analyses the vulnerability of decision tree-based models using the limited knowledge attack scenario. We considered the exploratory attack and implemented Zeroth Order Optimization adversarial attack on the detection models.