 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRudder: A Cross Lingual Video and Text Retrieval Dataset
Mar 09, 2021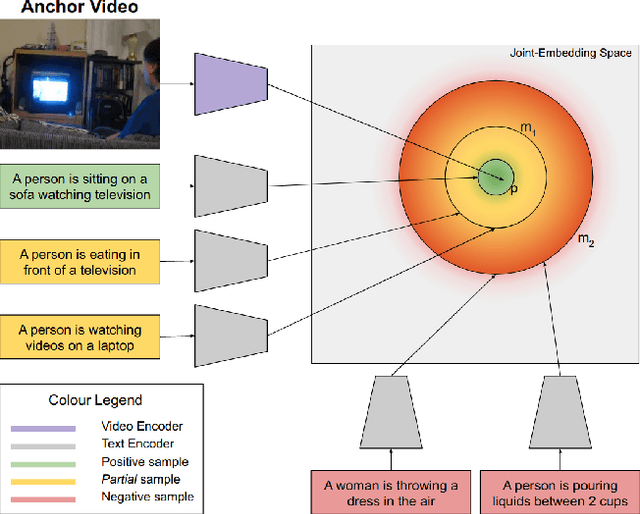
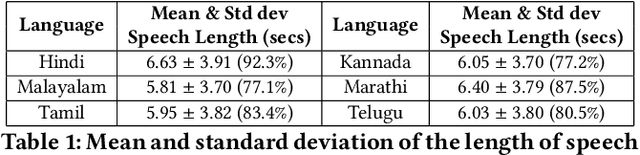
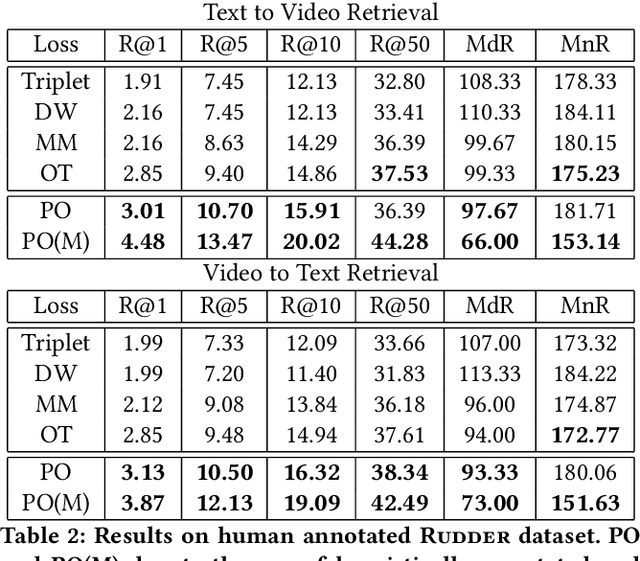
Video retrieval using natural language queries requires learning semantically meaningful joint embeddings between the text and the audio-visual input. Often, such joint embeddings are learnt using pairwise (or triplet) contrastive loss objectives which cannot give enough attention to 'difficult-to-retrieve' samples during training. This problem is especially pronounced in data-scarce settings where the data is relatively small (10% of the large scale MSR-VTT) to cover the rather complex audio-visual embedding space. In this context, we introduce Rudder - a multilingual video-text retrieval dataset that includes audio and textual captions in Marathi, Hindi, Tamil, Kannada, Malayalam and Telugu. Furthermore, we propose to compensate for data scarcity by using domain knowledge to augment supervision. To this end, in addition to the conventional three samples of a triplet (anchor, positive, and negative), we introduce a fourth term - a partial - to define a differential margin based partialorder loss. The partials are heuristically sampled such that they semantically lie in the overlap zone between the positives and the negatives, thereby resulting in broader embedding coverage. Our proposals consistently outperform the conventional max-margin and triplet losses and improve the state-of-the-art on MSR-VTT and DiDeMO datasets. We report benchmark results on Rudder while also observing significant gains using the proposed partial order loss, especially when the language specific retrieval models are jointly trained by availing the cross-lingual alignment across the language-specific datasets.