 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal learning for Audio-Visual Video Parsing
Apr 03, 2021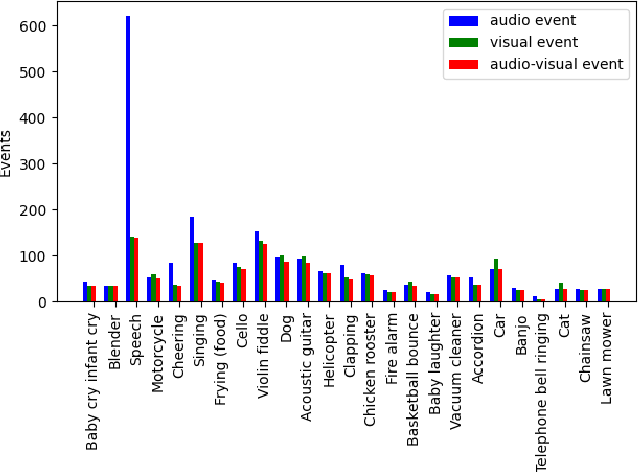
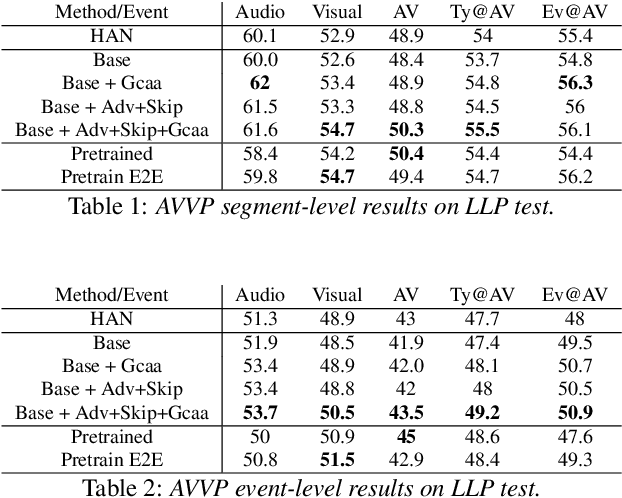
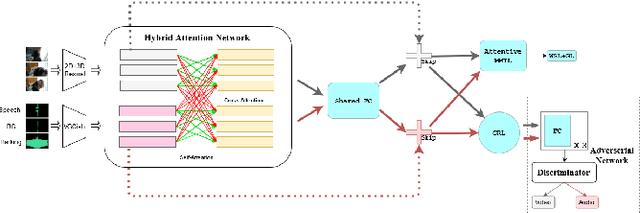

In this paper we present a novel approach to the Audio-visual video parsing task that takes into cognizance how event categories bind to audio and visual modalities. The proposed parsing approach simultaneously detects the temporal boundaries in terms of start and end times of such events. This task can be naturally formulated as a Multimodal Multiple Instance Learning (MMIL) problem. We show how the MMIL task can benefit from the following techniques geared toward self and cross modal learning: (i) self-supervised pre-training based on highly aligned task audio-video grounding, (ii) global context aware attention and (iii) adversarial training. As for pre-training, we boostrap on the Uniter (style) %\todo{add citation} transformer architecture using a self-supervised objective audio-video grounding over the relatively large AudioSet dataset. This pretrained model is fine-tuned on an architectural variant of the state-of-the-art Hybrid Attention Network (HAN) %\todo{Add citation} that uses global context aware attention and adversarial training objectives for audio visual video parsing. %Further, we use a hybrid attention network and adversarial training to improve self and cross modal learning. Attentive MMIL pooling method is leveraged to adaptively explore useful audio and visual signals from different temporal segments and modalities. We present extensive experimental evaluations on the Look, Listen, and Parse (LLP) dataset and compare it against HAN. We also present several ablation tests to validate the effect of pre-training, attention and adversarial training.