 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of the Area and Precipitation Associated with a Tropical Cyclone Biparjoy by using Image Processing
Jul 07, 2024The rainfall associated with Topical Cyclone(TC) contributes a major amount to the annual rainfall in India. Due to the limited research on the quantitative precipitation associated with Tropical Cyclones (TC), the prediction of the amount of precipitation and area that it may cover remains a challenge. This paper proposes an approach to estimate the accumulated precipitation and impact on affected area using Remote Sensing data. For this study, an instance of Extremely Severe Cyclonic Storm, Biparjoy that formed over the Arabian Sea and hit India in 2023 is considered in which we have used the satellite images of IMERG-Late Run of Global Precipitation Measurement (GPM). Image processing techniques were employed to identify and extract precipitation clusters linked to the cyclone. The results indicate that Biparjoy contributed a daily average rainfall of 53.14 mm/day across India and the Arabian Sea, with the Indian boundary receiving 11.59 mm/day, covering an extensive 411.76 thousand square kilometers. The localized intensity and variability observed in states like Gujarat, Rajasthan, Madhya Pradesh, and Uttar Pradesh highlight the need for tailored response measures, emphasizing the importance of further research to enhance predictive models and disaster readiness, crucial for building resilience against the diverse impacts of tropical cyclones.
Perturbing the Gradient for Alleviating Meta Overfitting
May 20, 2024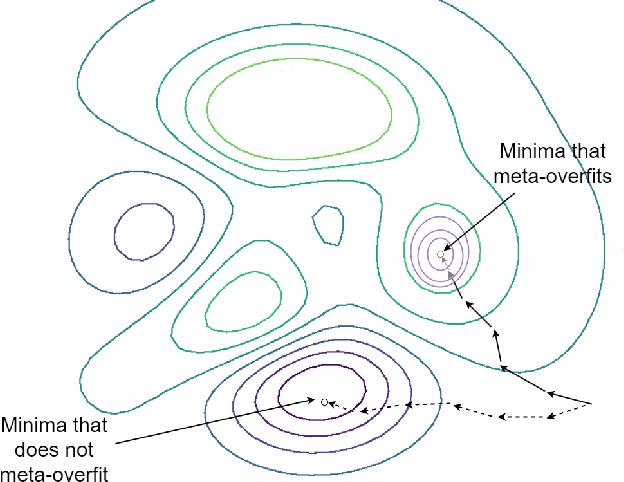
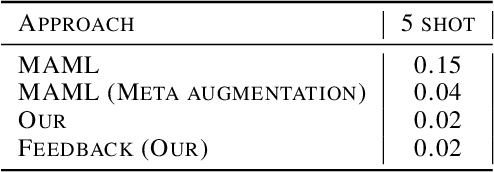
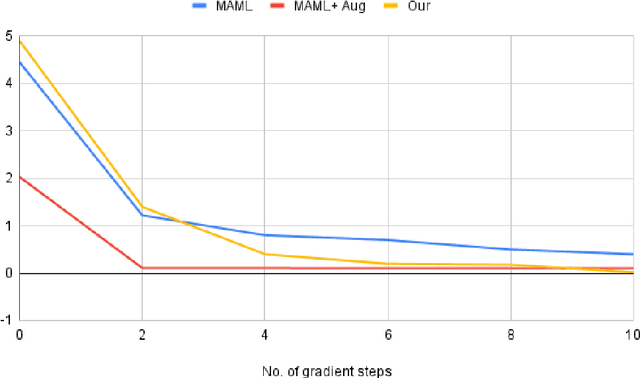
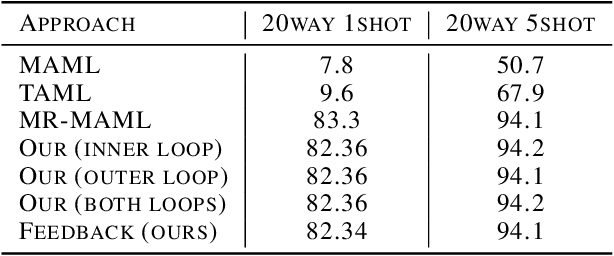
The reason for Meta Overfitting can be attributed to two factors: Mutual Non-exclusivity and the Lack of diversity, consequent to which a single global function can fit the support set data of all the meta-training tasks and fail to generalize to new unseen tasks. This issue is evidenced by low error rates on the meta-training tasks, but high error rates on new tasks. However, there can be a number of novel solutions to this problem keeping in mind any of the two objectives to be attained, i.e. to increase diversity in the tasks and to reduce the confidence of the model for some of the tasks. In light of the above, this paper proposes a number of solutions to tackle meta-overfitting on few-shot learning settings, such as few-shot sinusoid regression and few shot classification. Our proposed approaches demonstrate improved generalization performance compared to state-of-the-art baselines for learning in a non-mutually exclusive task setting. Overall, this paper aims to provide insights into tackling overfitting in meta-learning and to advance the field towards more robust and generalizable models.
Equitable-FL: Federated Learning with Sparsity for Resource-Constrained Environment
Sep 02, 2023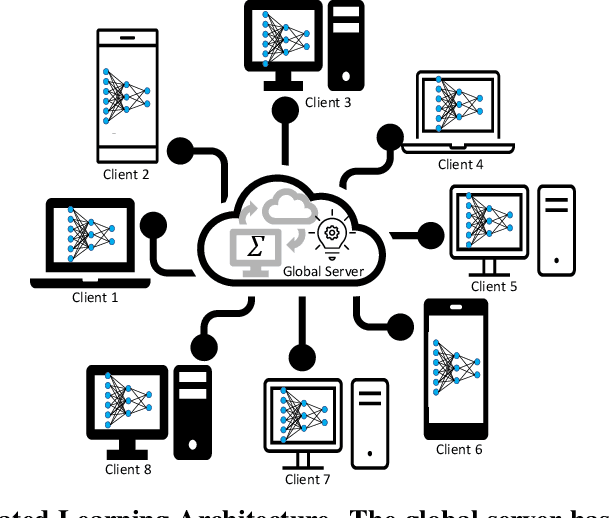
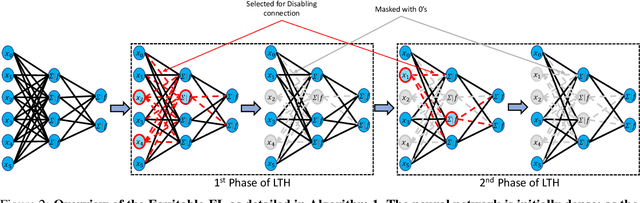
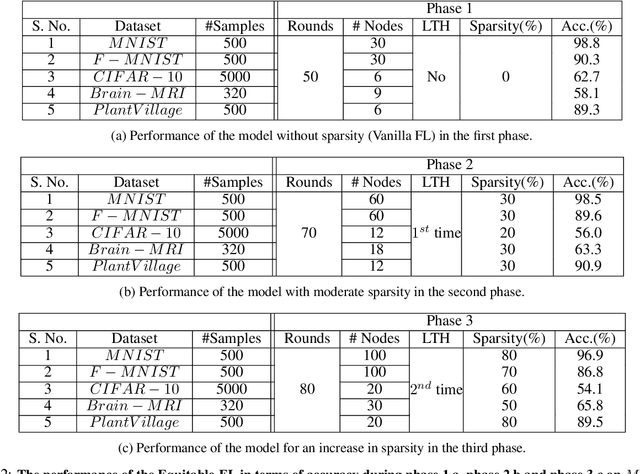
In Federated Learning, model training is performed across multiple computing devices, where only parameters are shared with a common central server without exchanging their data instances. This strategy assumes abundance of resources on individual clients and utilizes these resources to build a richer model as user's models. However, when the assumption of the abundance of resources is violated, learning may not be possible as some nodes may not be able to participate in the process. In this paper, we propose a sparse form of federated learning that performs well in a Resource Constrained Environment. Our goal is to make learning possible, regardless of a node's space, computing, or bandwidth scarcity. The method is based on the observation that model size viz a viz available resources defines resource scarcity, which entails that reduction of the number of parameters without affecting accuracy is key to model training in a resource-constrained environment. In this work, the Lottery Ticket Hypothesis approach is utilized to progressively sparsify models to encourage nodes with resource scarcity to participate in collaborative training. We validate Equitable-FL on the $MNIST$, $F-MNIST$, and $CIFAR-10$ benchmark datasets, as well as the $Brain-MRI$ data and the $PlantVillage$ datasets. Further, we examine the effect of sparsity on performance, model size compaction, and speed-up for training. Results obtained from experiments performed for training convolutional neural networks validate the efficacy of Equitable-FL in heterogeneous resource-constrained learning environment.
FAM: fast adaptive federated meta-learning
Sep 01, 2023
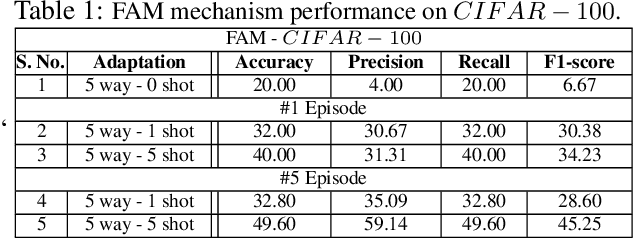
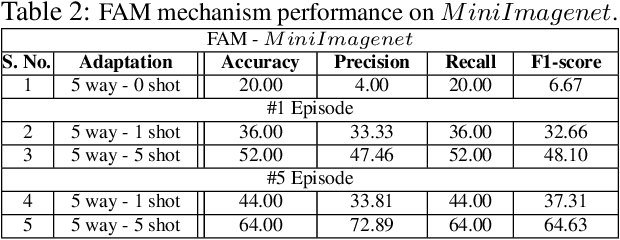
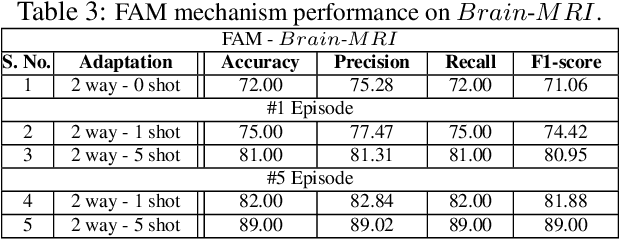
In this work, we propose a fast adaptive federated meta-learning (FAM) framework for collaboratively learning a single global model, which can then be personalized locally on individual clients. Federated learning enables multiple clients to collaborate to train a model without sharing data. Clients with insufficient data or data diversity participate in federated learning to learn a model with superior performance. Nonetheless, learning suffers when data distributions diverge. There is a need to learn a global model that can be adapted using client's specific information to create personalized models on clients is required. MRI data suffers from this problem, wherein, one, due to data acquisition challenges, local data at a site is sufficient for training an accurate model and two, there is a restriction of data sharing due to privacy concerns and three, there is a need for personalization of a learnt shared global model on account of domain shift across client sites. The global model is sparse and captures the common features in the MRI. This skeleton network is grown on each client to train a personalized model by learning additional client-specific parameters from local data. Experimental results show that the personalization process at each client quickly converges using a limited number of epochs. The personalized client models outperformed the locally trained models, demonstrating the efficacy of the FAM mechanism. Additionally, the sparse parameter set to be communicated during federated learning drastically reduced communication overhead, which makes the scheme viable for networks with limited resources.
Deep Learning Techniques in Extreme Weather Events: A Review
Aug 18, 2023Extreme weather events pose significant challenges, thereby demanding techniques for accurate analysis and precise forecasting to mitigate its impact. In recent years, deep learning techniques have emerged as a promising approach for weather forecasting and understanding the dynamics of extreme weather events. This review aims to provide a comprehensive overview of the state-of-the-art deep learning in the field. We explore the utilization of deep learning architectures, across various aspects of weather prediction such as thunderstorm, lightning, precipitation, drought, heatwave, cold waves and tropical cyclones. We highlight the potential of deep learning, such as its ability to capture complex patterns and non-linear relationships. Additionally, we discuss the limitations of current approaches and highlight future directions for advancements in the field of meteorology. The insights gained from this systematic review are crucial for the scientific community to make informed decisions and mitigate the impacts of extreme weather events.
Learning to Learn with Indispensable Connections
Apr 06, 2023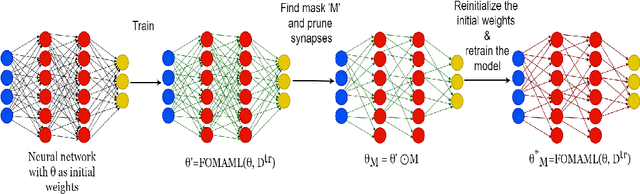
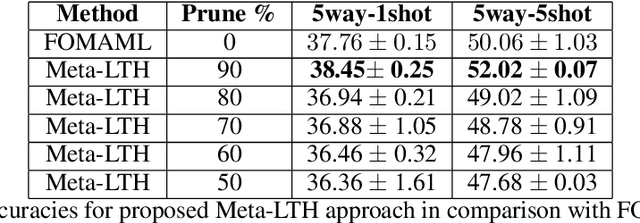
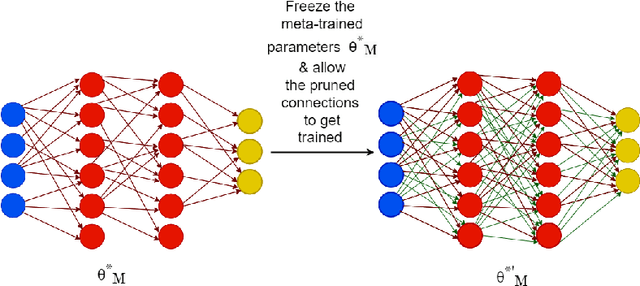
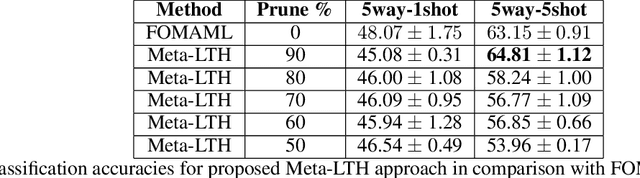
Meta-learning aims to solve unseen tasks with few labelled instances. Nevertheless, despite its effectiveness for quick learning in existing optimization-based methods, it has several flaws. Inconsequential connections are frequently seen during meta-training, which results in an over-parameterized neural network. Because of this, meta-testing observes unnecessary computations and extra memory overhead. To overcome such flaws. We propose a novel meta-learning method called Meta-LTH that includes indispensible (necessary) connections. We applied the lottery ticket hypothesis technique known as magnitude pruning to generate these crucial connections that can effectively solve few-shot learning problem. We aim to perform two things: (a) to find a sub-network capable of more adaptive meta-learning and (b) to learn new low-level features of unseen tasks and recombine those features with the already learned features during the meta-test phase. Experimental results show that our proposed Met-LTH method outperformed existing first-order MAML algorithm for three different classification datasets. Our method improves the classification accuracy by approximately 2% (20-way 1-shot task setting) for omniglot dataset.
Hybrid Model using Feature Extraction and Non-linear SVM for Brain Tumor Classification
Dec 06, 2022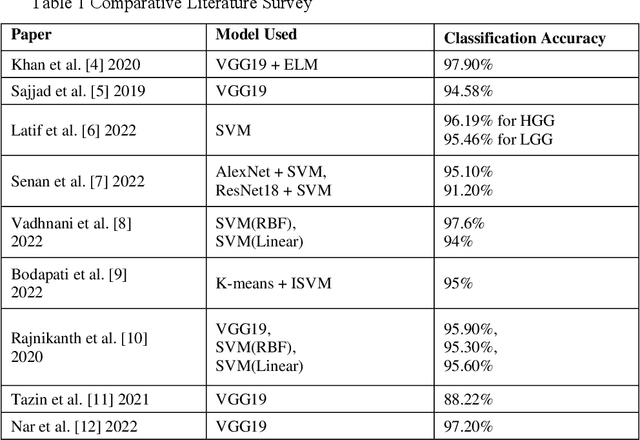

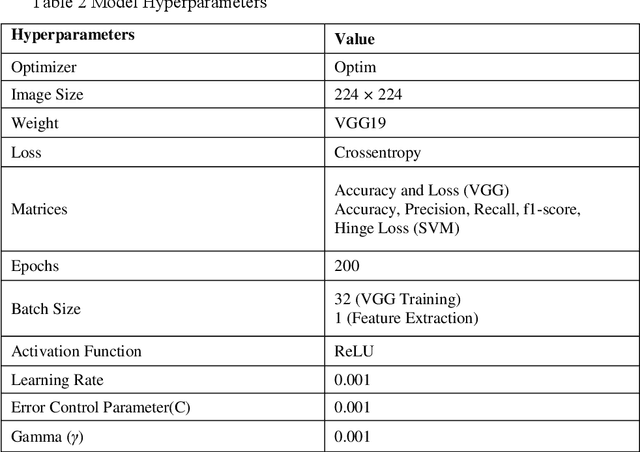

It is essential to classify brain tumors from magnetic resonance imaging (MRI) accurately for better and timely treatment of the patients. In this paper, we propose a hybrid model, using VGG along with Nonlinear-SVM (Soft and Hard) to classify the brain tumors: glioma and pituitary and tumorous and non-tumorous. The VGG-SVM model is trained for two different datasets of two classes; thus, we perform binary classification. The VGG models are trained via the PyTorch python library to obtain the highest testing accuracy of tumor classification. The method is threefold, in the first step, we normalize and resize the images, and the second step consists of feature extraction through variants of the VGG model. The third step classified brain tumors using non-linear SVM (soft and hard). We have obtained 98.18% accuracy for the first dataset and 99.78% for the second dataset using VGG19. The classification accuracies for non-linear SVM are 95.50% and 97.98% with linear and rbf kernel and 97.95% for soft SVM with RBF kernel with D1, and 96.75% and 98.60% with linear and RBF kernel and 98.38% for soft SVM with RBF kernel with D2. Results indicate that the hybrid VGG-SVM model, especially VGG 19 with SVM, is able to outperform existing techniques and achieve high accuracy.
Adaptive Prototypical Networks
Nov 22, 2022Prototypical network for Few shot learning tries to learn an embedding function in the encoder that embeds images with similar features close to one another in the embedding space. However, in this process, the support set samples for a task are embedded independently of one other, and hence, the inter-class closeness is not taken into account. Thus, in the presence of similar-looking classes in a task, the embeddings will tend to be close to each other in the embedding space and even possibly overlap in some regions, which is not desirable for classification. In this paper, we propose an approach that intuitively pushes the embeddings of each of the classes away from the others in the meta-testing phase, thereby grouping them closely based on the distinct class labels rather than only the similarity of spatial features. This is achieved by training the encoder network for classification using the support set samples and labels of the new task. Extensive experiments conducted on benchmark data sets show improvements in meta-testing accuracy when compared with Prototypical Networks and also other standard few-shot learning models.
Parzen Window Approximation on Riemannian Manifold
Dec 29, 2020

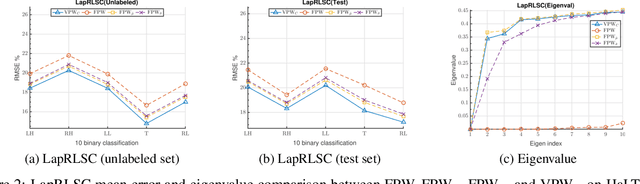
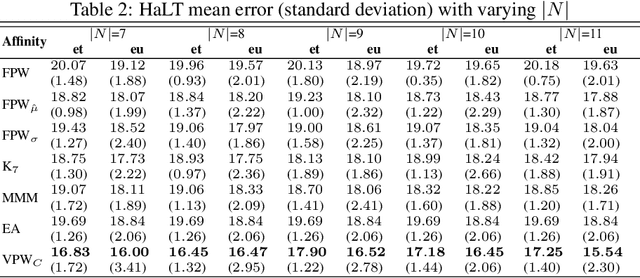
In graph motivated learning, label propagation largely depends on data affinity represented as edges between connected data points. The affinity assignment implicitly assumes even distribution of data on the manifold. This assumption may not hold and may lead to inaccurate metric assignment due to drift towards high-density regions. The drift affected heat kernel based affinity with a globally fixed Parzen window either discards genuine neighbors or forces distant data points to become a member of the neighborhood. This yields a biased affinity matrix. In this paper, the bias due to uneven data sampling on the Riemannian manifold is catered to by a variable Parzen window determined as a function of neighborhood size, ambient dimension, flatness range, etc. Additionally, affinity adjustment is used which offsets the effect of uneven sampling responsible for the bias. An affinity metric which takes into consideration the irregular sampling effect to yield accurate label propagation is proposed. Extensive experiments on synthetic and real-world data sets confirm that the proposed method increases the classification accuracy significantly and outperforms existing Parzen window estimators in graph Laplacian manifold regularization methods.