 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquitable-FL: Federated Learning with Sparsity for Resource-Constrained Environment
Sep 02, 2023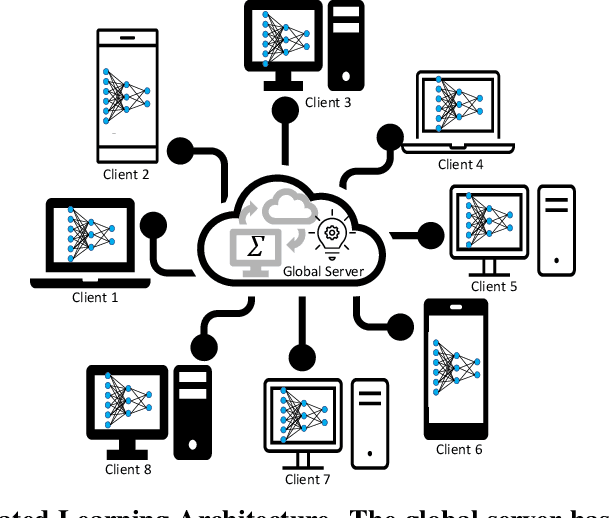
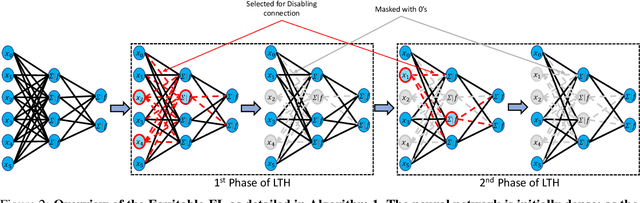
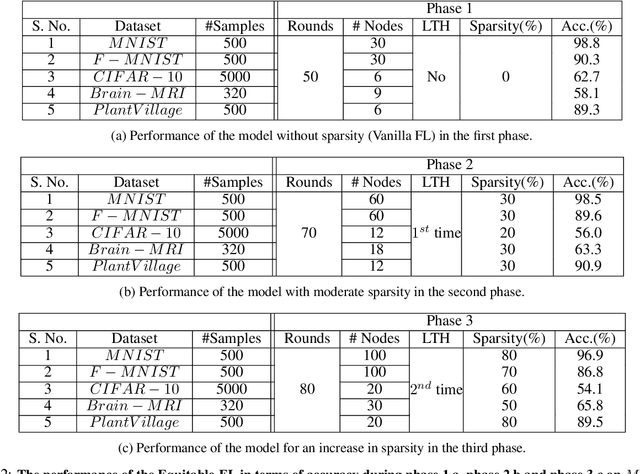
In Federated Learning, model training is performed across multiple computing devices, where only parameters are shared with a common central server without exchanging their data instances. This strategy assumes abundance of resources on individual clients and utilizes these resources to build a richer model as user's models. However, when the assumption of the abundance of resources is violated, learning may not be possible as some nodes may not be able to participate in the process. In this paper, we propose a sparse form of federated learning that performs well in a Resource Constrained Environment. Our goal is to make learning possible, regardless of a node's space, computing, or bandwidth scarcity. The method is based on the observation that model size viz a viz available resources defines resource scarcity, which entails that reduction of the number of parameters without affecting accuracy is key to model training in a resource-constrained environment. In this work, the Lottery Ticket Hypothesis approach is utilized to progressively sparsify models to encourage nodes with resource scarcity to participate in collaborative training. We validate Equitable-FL on the $MNIST$, $F-MNIST$, and $CIFAR-10$ benchmark datasets, as well as the $Brain-MRI$ data and the $PlantVillage$ datasets. Further, we examine the effect of sparsity on performance, model size compaction, and speed-up for training. Results obtained from experiments performed for training convolutional neural networks validate the efficacy of Equitable-FL in heterogeneous resource-constrained learning environment.
FAM: fast adaptive federated meta-learning
Sep 01, 2023
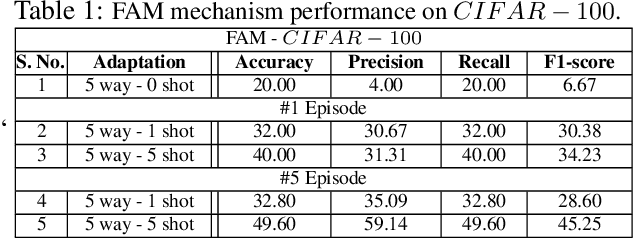
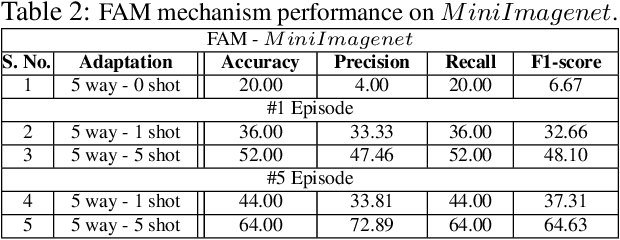
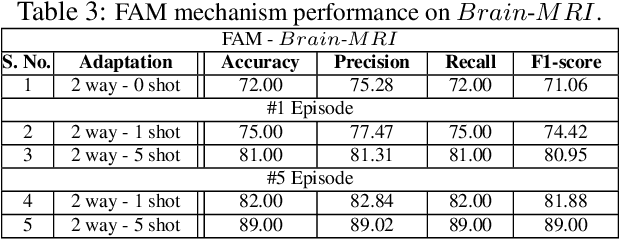
In this work, we propose a fast adaptive federated meta-learning (FAM) framework for collaboratively learning a single global model, which can then be personalized locally on individual clients. Federated learning enables multiple clients to collaborate to train a model without sharing data. Clients with insufficient data or data diversity participate in federated learning to learn a model with superior performance. Nonetheless, learning suffers when data distributions diverge. There is a need to learn a global model that can be adapted using client's specific information to create personalized models on clients is required. MRI data suffers from this problem, wherein, one, due to data acquisition challenges, local data at a site is sufficient for training an accurate model and two, there is a restriction of data sharing due to privacy concerns and three, there is a need for personalization of a learnt shared global model on account of domain shift across client sites. The global model is sparse and captures the common features in the MRI. This skeleton network is grown on each client to train a personalized model by learning additional client-specific parameters from local data. Experimental results show that the personalization process at each client quickly converges using a limited number of epochs. The personalized client models outperformed the locally trained models, demonstrating the efficacy of the FAM mechanism. Additionally, the sparse parameter set to be communicated during federated learning drastically reduced communication overhead, which makes the scheme viable for networks with limited resources.
DenseBAM-GI: Attention Augmented DeneseNet with momentum aided GRU for HMER
Jun 28, 2023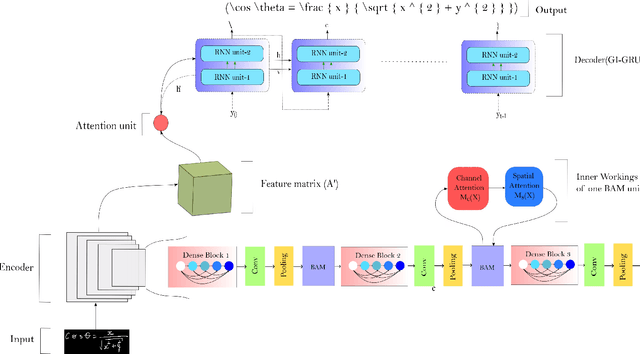
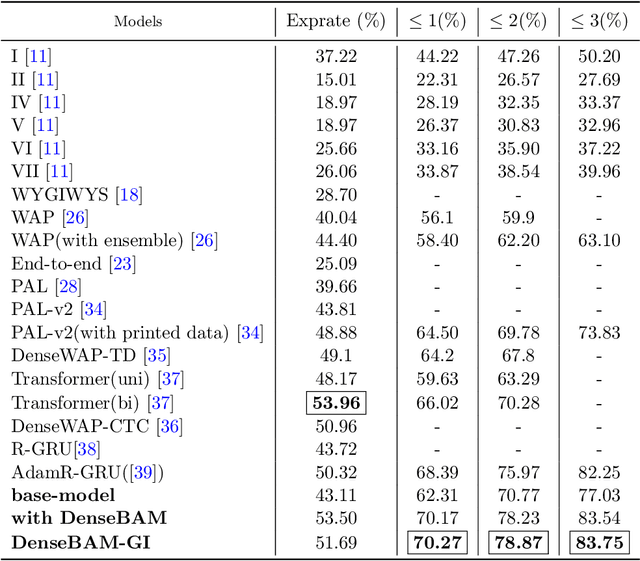
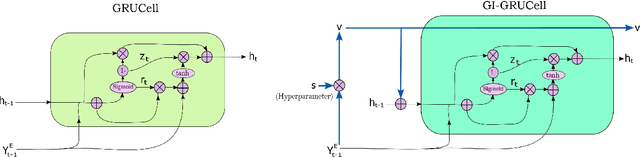
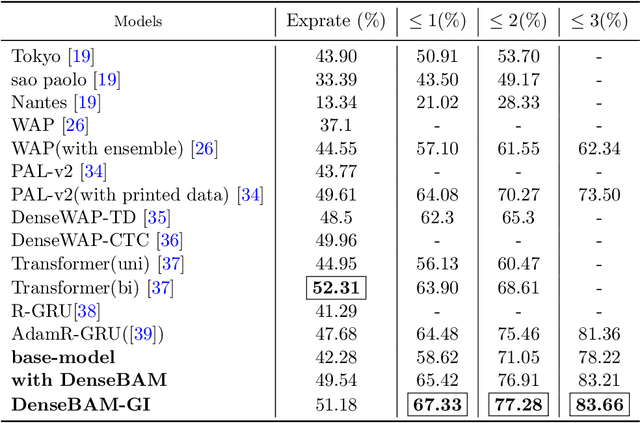
The task of recognising Handwritten Mathematical Expressions (HMER) is crucial in the fields of digital education and scholarly research. However, it is difficult to accurately determine the length and complex spatial relationships among symbols in handwritten mathematical expressions. In this study, we present a novel encoder-decoder architecture (DenseBAM-GI) for HMER, where the encoder has a Bottleneck Attention Module (BAM) to improve feature representation and the decoder has a Gated Input-GRU (GI-GRU) unit with an extra gate to make decoding long and complex expressions easier. The proposed model is an efficient and lightweight architecture with performance equivalent to state-of-the-art models in terms of Expression Recognition Rate (exprate). It also performs better in terms of top 1, 2, and 3 error accuracy across the CROHME 2014, 2016, and 2019 datasets. DenseBAM-GI achieves the best exprate among all models on the CROHME 2019 dataset. Importantly, these successes are accomplished with a drop in the complexity of the calculation and a reduction in the need for GPU memory.
Learning to Learn with Indispensable Connections
Apr 06, 2023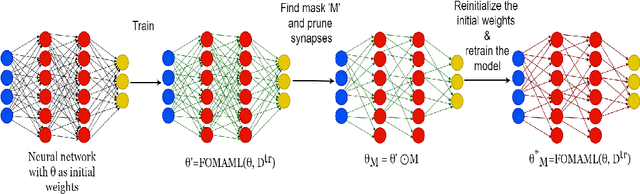
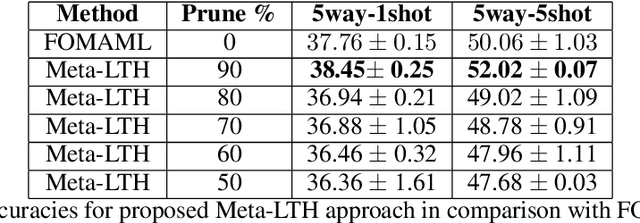
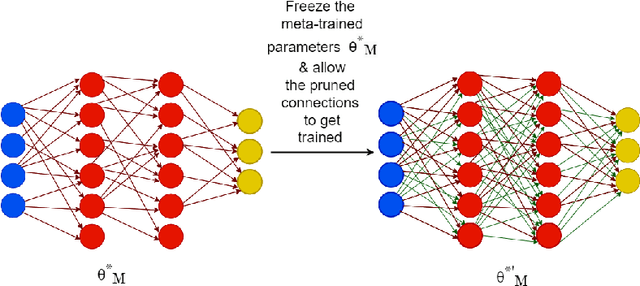
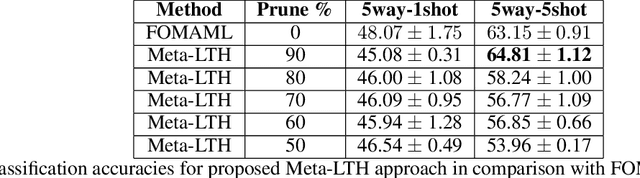
Meta-learning aims to solve unseen tasks with few labelled instances. Nevertheless, despite its effectiveness for quick learning in existing optimization-based methods, it has several flaws. Inconsequential connections are frequently seen during meta-training, which results in an over-parameterized neural network. Because of this, meta-testing observes unnecessary computations and extra memory overhead. To overcome such flaws. We propose a novel meta-learning method called Meta-LTH that includes indispensible (necessary) connections. We applied the lottery ticket hypothesis technique known as magnitude pruning to generate these crucial connections that can effectively solve few-shot learning problem. We aim to perform two things: (a) to find a sub-network capable of more adaptive meta-learning and (b) to learn new low-level features of unseen tasks and recombine those features with the already learned features during the meta-test phase. Experimental results show that our proposed Met-LTH method outperformed existing first-order MAML algorithm for three different classification datasets. Our method improves the classification accuracy by approximately 2% (20-way 1-shot task setting) for omniglot dataset.
Signature Verification using Geometrical Features and Artificial Neural Network Classifier
Aug 04, 2021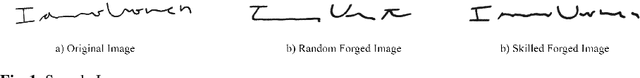
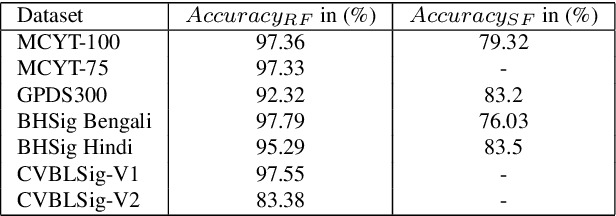
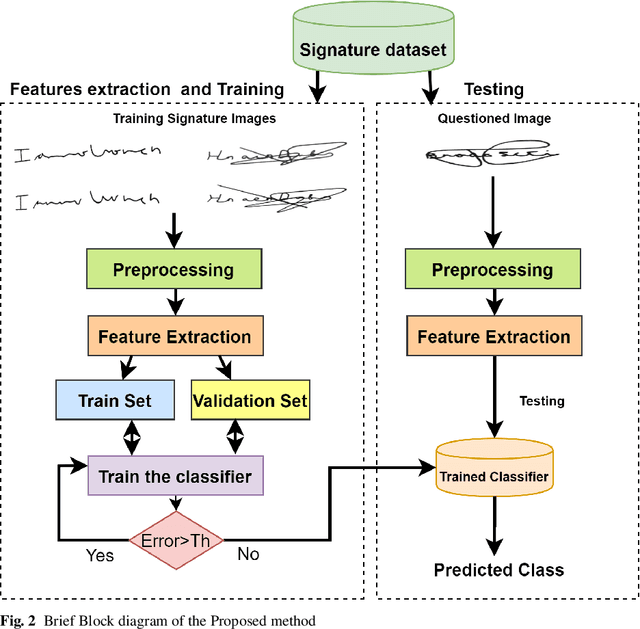
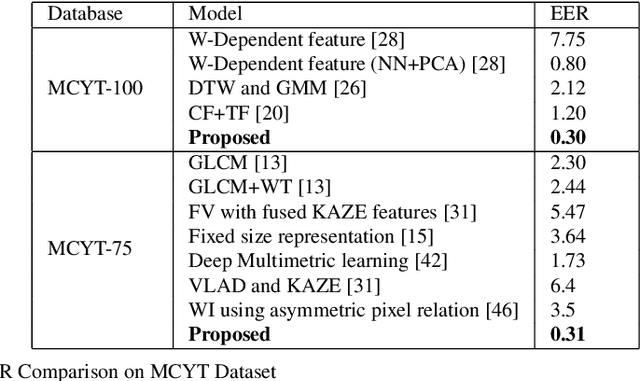
Signature verification has been one of the major researched areas in the field of computer vision. Many financial and legal organizations use signature verification as access control and authentication. Signature images are not rich in texture; however, they have much vital geometrical information. Through this work, we have proposed a signature verification methodology that is simple yet effective. The technique presented in this paper harnesses the geometrical features of a signature image like center, isolated points, connected components, etc., and with the power of Artificial Neural Network (ANN) classifier, classifies the signature image based on their geometrical features. Publicly available dataset MCYT, BHSig260 (contains the image of two regional languages Bengali and Hindi) has been used in this paper to test the effectiveness of the proposed method. We have received a lower Equal Error Rate (EER) on MCYT 100 dataset and higher accuracy on the BHSig260 dataset.