 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbing the Gradient for Alleviating Meta Overfitting
May 20, 2024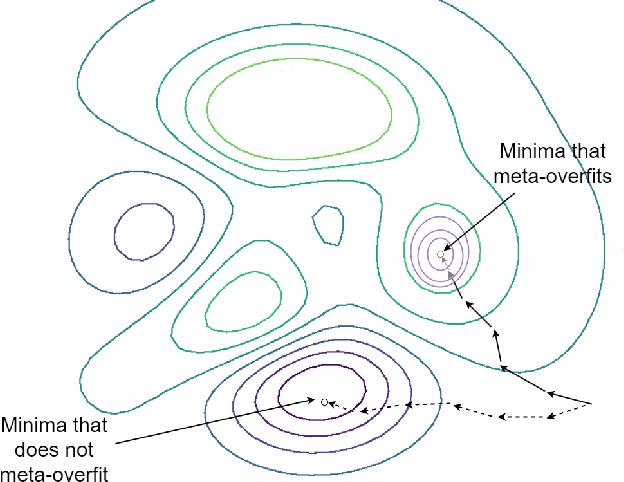
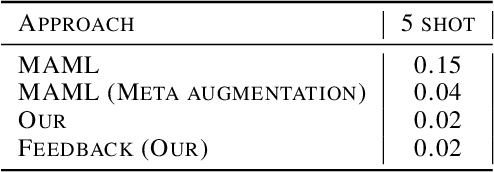
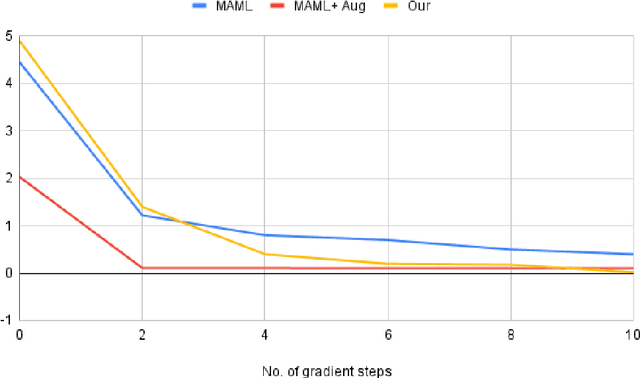
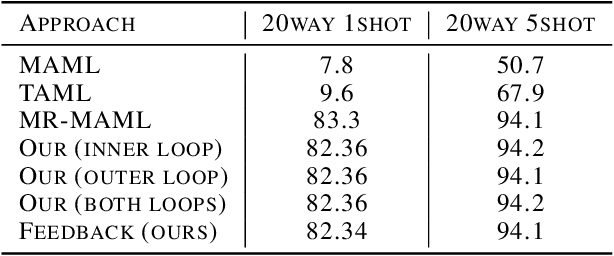
The reason for Meta Overfitting can be attributed to two factors: Mutual Non-exclusivity and the Lack of diversity, consequent to which a single global function can fit the support set data of all the meta-training tasks and fail to generalize to new unseen tasks. This issue is evidenced by low error rates on the meta-training tasks, but high error rates on new tasks. However, there can be a number of novel solutions to this problem keeping in mind any of the two objectives to be attained, i.e. to increase diversity in the tasks and to reduce the confidence of the model for some of the tasks. In light of the above, this paper proposes a number of solutions to tackle meta-overfitting on few-shot learning settings, such as few-shot sinusoid regression and few shot classification. Our proposed approaches demonstrate improved generalization performance compared to state-of-the-art baselines for learning in a non-mutually exclusive task setting. Overall, this paper aims to provide insights into tackling overfitting in meta-learning and to advance the field towards more robust and generalizable models.
Learning to Learn with Indispensable Connections
Apr 06, 2023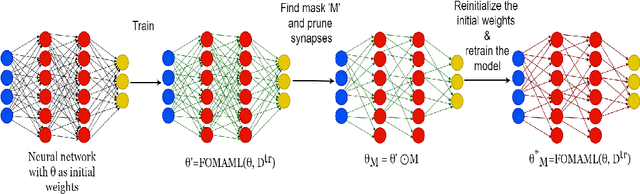
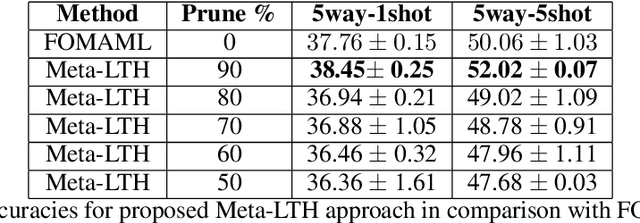
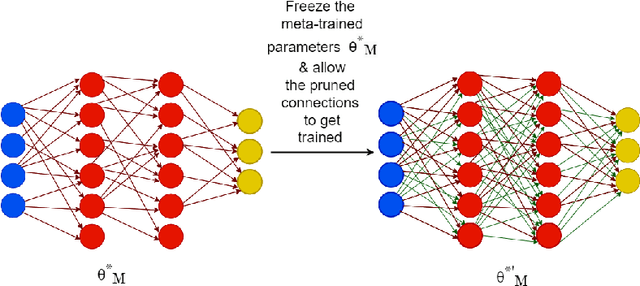
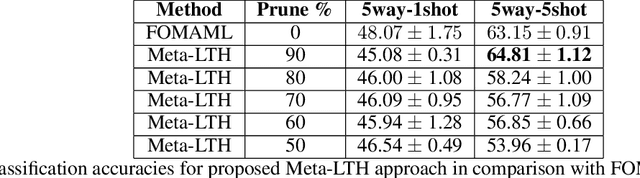
Meta-learning aims to solve unseen tasks with few labelled instances. Nevertheless, despite its effectiveness for quick learning in existing optimization-based methods, it has several flaws. Inconsequential connections are frequently seen during meta-training, which results in an over-parameterized neural network. Because of this, meta-testing observes unnecessary computations and extra memory overhead. To overcome such flaws. We propose a novel meta-learning method called Meta-LTH that includes indispensible (necessary) connections. We applied the lottery ticket hypothesis technique known as magnitude pruning to generate these crucial connections that can effectively solve few-shot learning problem. We aim to perform two things: (a) to find a sub-network capable of more adaptive meta-learning and (b) to learn new low-level features of unseen tasks and recombine those features with the already learned features during the meta-test phase. Experimental results show that our proposed Met-LTH method outperformed existing first-order MAML algorithm for three different classification datasets. Our method improves the classification accuracy by approximately 2% (20-way 1-shot task setting) for omniglot dataset.
Adaptive Prototypical Networks
Nov 22, 2022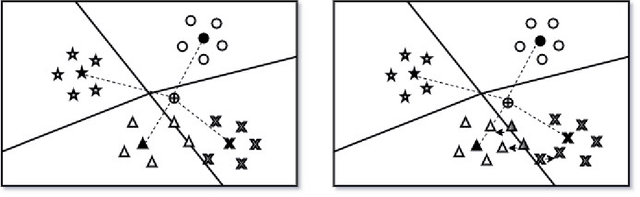



Prototypical network for Few shot learning tries to learn an embedding function in the encoder that embeds images with similar features close to one another in the embedding space. However, in this process, the support set samples for a task are embedded independently of one other, and hence, the inter-class closeness is not taken into account. Thus, in the presence of similar-looking classes in a task, the embeddings will tend to be close to each other in the embedding space and even possibly overlap in some regions, which is not desirable for classification. In this paper, we propose an approach that intuitively pushes the embeddings of each of the classes away from the others in the meta-testing phase, thereby grouping them closely based on the distinct class labels rather than only the similarity of spatial features. This is achieved by training the encoder network for classification using the support set samples and labels of the new task. Extensive experiments conducted on benchmark data sets show improvements in meta-testing accuracy when compared with Prototypical Networks and also other standard few-shot learning models.