 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Detail Left Behind: Revisiting Self-Retrieval for Fine-Grained Image Captioning
Sep 04, 2024
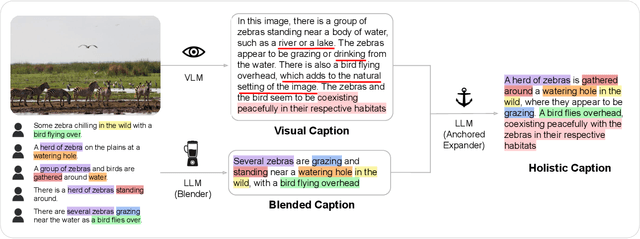
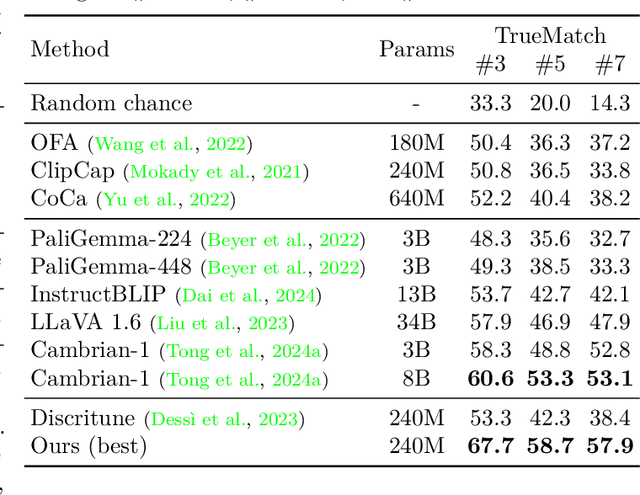
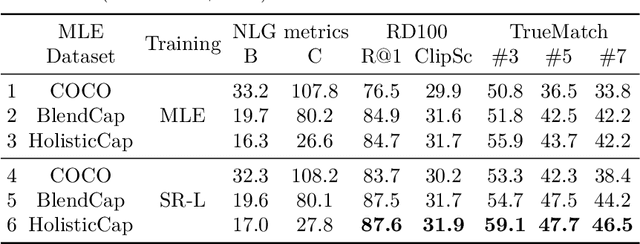
Image captioning systems are unable to generate fine-grained captions as they are trained on data that is either noisy (alt-text) or generic (human annotations). This is further exacerbated by maximum likelihood training that encourages generation of frequently occurring phrases. Previous works have tried to address this limitation by fine-tuning captioners with a self-retrieval (SR) reward. However, we find that SR fine-tuning has a tendency to reduce caption faithfulness and even hallucinate. In this work, we circumvent this bottleneck by improving the MLE initialization of the captioning system and designing a curriculum for the SR fine-tuning process. To this extent, we present (1) Visual Caption Boosting, a novel framework to instill fine-grainedness in generic image captioning datasets while remaining anchored in human annotations; and (2) BagCurri, a carefully designed training curriculum that more optimally leverages the contrastive nature of the self-retrieval reward. Jointly, they enable the captioner to describe fine-grained aspects in the image while preserving faithfulness to ground-truth captions. Our approach outperforms previous work by +8.9% on SR against 99 random distractors (RD100) (Dessi et al., 2023); and +7.6% on ImageCoDe. Additionally, existing metrics to evaluate captioning systems fail to reward diversity or evaluate a model's fine-grained understanding ability. Our third contribution addresses this by proposing self-retrieval from the lens of evaluation. We introduce TrueMatch, a benchmark comprising bags of highly similar images that uses SR to assess the captioner's ability to capture subtle visual distinctions. We evaluate and compare several state-of-the-art open-source MLLMs on TrueMatch, and find that our SR approach outperforms them all by a significant margin (e.g. +4.8% - 7.1% over Cambrian) while having 1-2 orders of magnitude fewer parameters.
FiGCLIP: Fine-Grained CLIP Adaptation via Densely Annotated Videos
Jan 15, 2024While contrastive language image pretraining (CLIP) have exhibited impressive performance by learning highly semantic and generalized representations, recent works have exposed a fundamental drawback in its syntactic properties, that includes interpreting fine-grained attributes, actions, spatial relations, states, and details that require compositional reasoning. One reason for this is that natural captions often do not capture all the visual details of a scene. This leads to unaddressed visual concepts being misattributed to the wrong words. And the pooled image and text features, ends up acting as a bag of words, hence losing the syntactic information. In this work, we ask: Is it possible to enhance CLIP's fine-grained and syntactic abilities without compromising its semantic properties? We show that this is possible by adapting CLIP efficiently on a high-quality, comprehensive, and relatively small dataset. We demonstrate our adaptation strategy on VidSitu, a video situation recognition dataset annotated with verbs and rich semantic role labels (SRL). We use the SRL and verb information to create rule-based detailed captions, making sure they capture most of the visual concepts. Combined with hard negatives and hierarchical losses, these annotations allow us to learn a powerful visual representation, dubbed Fine-Grained CLIP (FiGCLIP), that preserves semantic understanding while being detail-oriented. We evaluate on five diverse vision-language tasks in both fine-tuning and zero-shot settings, achieving consistent improvements over the base CLIP model.
Unsupervised Audio-Visual Lecture Segmentation
Oct 29, 2022
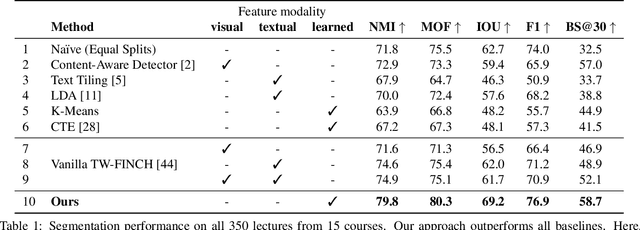
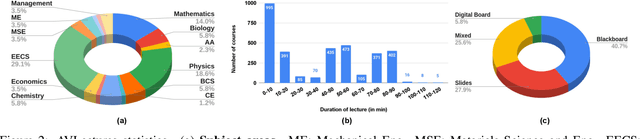

Over the last decade, online lecture videos have become increasingly popular and have experienced a meteoric rise during the pandemic. However, video-language research has primarily focused on instructional videos or movies, and tools to help students navigate the growing online lectures are lacking. Our first contribution is to facilitate research in the educational domain, by introducing AVLectures, a large-scale dataset consisting of 86 courses with over 2,350 lectures covering various STEM subjects. Each course contains video lectures, transcripts, OCR outputs for lecture frames, and optionally lecture notes, slides, assignments, and related educational content that can inspire a variety of tasks. Our second contribution is introducing video lecture segmentation that splits lectures into bite-sized topics that show promise in improving learner engagement. We formulate lecture segmentation as an unsupervised task that leverages visual, textual, and OCR cues from the lecture, while clip representations are fine-tuned on a pretext self-supervised task of matching the narration with the temporally aligned visual content. We use these representations to generate segments using a temporally consistent 1-nearest neighbor algorithm, TW-FINCH. We evaluate our method on 15 courses and compare it against various visual and textual baselines, outperforming all of them. Our comprehensive ablation studies also identify the key factors driving the success of our approach.