 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo ChatCaptioner: Towards Enriched Spatiotemporal Descriptions
Paper and Code
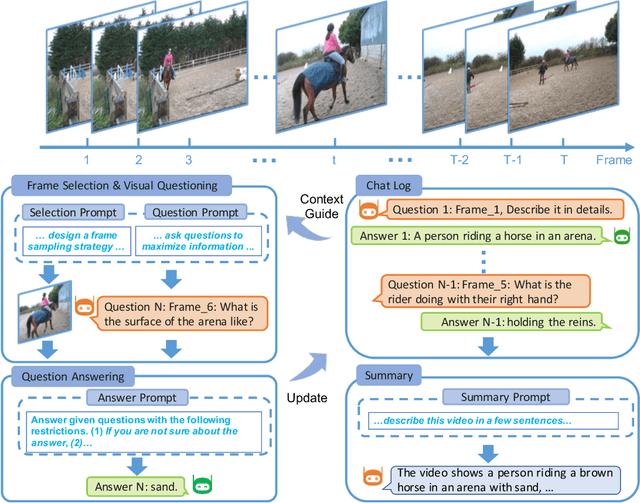



Video captioning aims to convey dynamic scenes from videos using natural language, facilitating the understanding of spatiotemporal information within our environment. Although there have been recent advances, generating detailed and enriched video descriptions continues to be a substantial challenge. In this work, we introduce Video ChatCaptioner, an innovative approach for creating more comprehensive spatiotemporal video descriptions. Our method employs a ChatGPT model as a controller, specifically designed to select frames for posing video content-driven questions. Subsequently, a robust algorithm is utilized to answer these visual queries. This question-answer framework effectively uncovers intricate video details and shows promise as a method for enhancing video content. Following multiple conversational rounds, ChatGPT can summarize enriched video content based on previous conversations. We qualitatively demonstrate that our Video ChatCaptioner can generate captions containing more visual details about the videos. The code is publicly available at https://github.com/Vision-CAIR/ChatCaptioner