 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-inferiority of Deep Learning Model to Segment Acute Stroke on Non-contrast CT Compared to Neuroradiologists
Nov 24, 2022Purpose: To develop a deep learning model to segment the acute ischemic infarct on non-contrast Computed Tomography (NCCT). Materials and Methods In this retrospective study, 227 Head NCCT examinations from 200 patients enrolled in the multicenter DEFUSE 3 trial were included. Three experienced neuroradiologists (experts A, B and C) independently segmented the acute infarct on each study. The dataset was randomly split into 5 folds with training and validation cases. A 3D deep Convolutional Neural Network (CNN) architecture was optimized for the data set properties and task needs. The input to the model was the NCCT and the output was a segmentation mask. The model was trained and optimized on expert A. The outcome was assessed by a set of volume, overlap and distance metrics. The predicted segmentations of the best model and expert A were compared to experts B and C. Then we used a paired Wilcoxon signed-rank test in a one-sided test procedure for all metrics to test for non-inferiority in terms of bias and precision. Results: The best performing model reached a Surface Dice at Tolerance (SDT)5mm of 0.68 \pm 0.04. The predictions were non-inferior when compared to independent experts in terms of bias and precision (paired one-sided test procedure for differences in medians and bootstrapped standard deviations with non-inferior boundaries of -0.05, 2ml, and 2mm, p < 0.05, n=200). Conclusion: For the segmentation of acute ischemic stroke on NCCT, our 3D CNN trained with the annotations of one neuroradiologist is non-inferior when compared to two independent neuroradiologists.
Evaluation of Medical Image Segmentation Models for Uncertain, Small or Empty Reference Annotations
Sep 30, 2022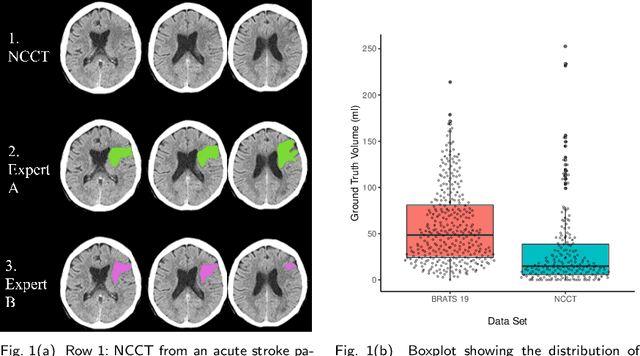

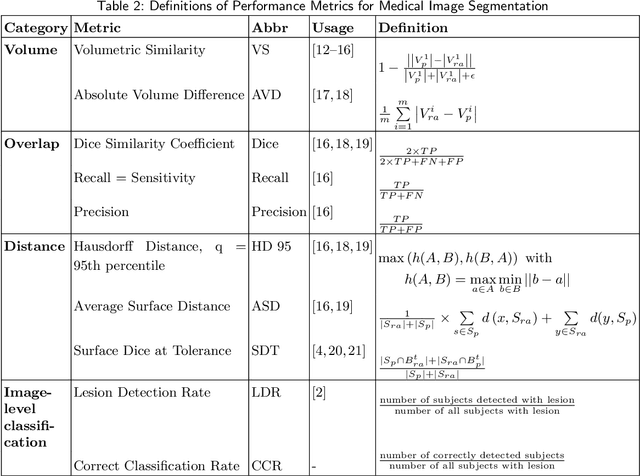
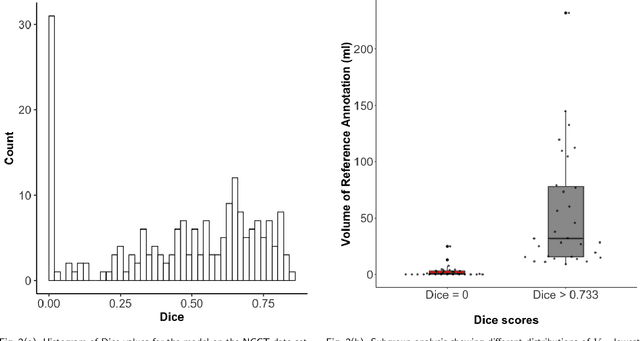
Performance metrics for medical image segmentation models are used to measure agreement between the reference annotation and the prediction. A common set of metrics is used in the development of such models to make results more comparable. However, there is a mismatch between the distributions in public data sets and cases encountered in clinical practice. Many common metrics fail to measure the impact of this mismatch, especially for clinical data sets containing uncertain, small or empty reference annotation. Thus, models may not be validated for clinically meaningful agreement by such metrics. Dimensions of evaluating clinical value include independence from reference annotation volume size, consideration of uncertainty of reference annotations, reward of volumetric and/or location agreement and reward of correct classification of empty reference annotations. Unlike common public data sets, our in-house data set is more representative. It contains uncertain, small or empty reference annotations. We examine publicly available metrics on the predictions of a deep learning framework in order to identify for which settings common metrics provide clinical meaningful results. We compare to a public benchmark data set without uncertain, small or empty reference annotations. https://github.com/SophieOstmeier/UncertainSmallEmpty
Improved Segmentation and Detection Sensitivity of Diffusion-Weighted Brain Infarct Lesions with Synthetically Enhanced Deep Learning
Dec 29, 2020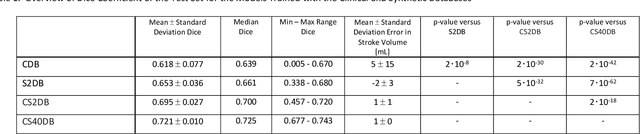
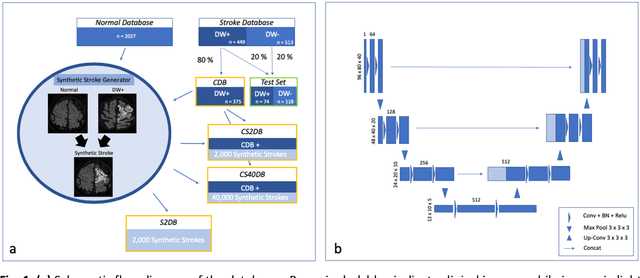
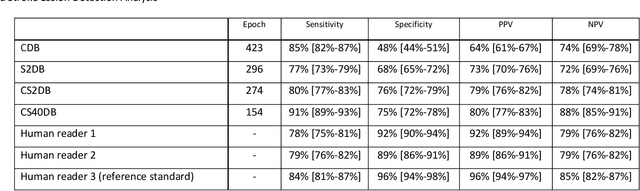
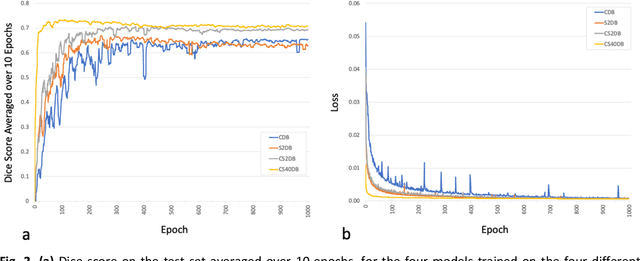
Purpose: To compare the segmentation and detection performance of a deep learning model trained on a database of human-labelled clinical diffusion-weighted (DW) stroke lesions to a model trained on the same database enhanced with synthetic DW stroke lesions. Methods: In this institutional review board approved study, a stroke database of 962 cases (mean age 65+/-17 years, 255 males, 449 scans with DW positive stroke lesions) and a normal database of 2,027 patients (mean age 38+/-24 years,1088 females) were obtained. Brain volumes with synthetic DW stroke lesions were produced by warping the relative signal increase of real strokes to normal brain volumes. A generic 3D U-Net was trained on four different databases to generate four different models: (a) 375 neuroradiologist-labeled clinical DW positive stroke cases(CDB);(b) 2,000 synthetic cases(S2DB);(c) CDB+2,000 synthetic cases(CS2DB); or (d) CDB+40,000 synthetic cases(CS40DB). The models were tested on 20%(n=192) of the cases of the stroke database, which were excluded from the training set. Segmentation accuracy was characterized using Dice score and lesion volume of the stroke segmentation, and statistical significance was tested using a paired, two-tailed, Student's t-test. Detection sensitivity and specificity was compared to three neuroradiologists. Results: The performance of the 3D U-Net model trained on the CS40DB(mean Dice 0.72) was better than models trained on the CS2DB (0.70,P <0.001) or the CDB(0.65,P<0.001). The deep learning model was also more sensitive (91%[89%-93%]) than each of the three human readers(84%[81%-87%],78%[75%-81%],and 79%[76%-82%]), but less specific(75%[72%-78%] vs for the three human readers (96%[94%-97%],92%[90%-94%] and 89%[86%-91%]). Conclusion: Deep learning training for segmentation and detection of DW stroke lesions was significantly improved by enhancing the training set with synthetic lesions.
* This manuscript has been accepted for publication in Radiology: Artificial Intelligence