 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamically Grown Generative Adversarial Networks
Jun 16, 2021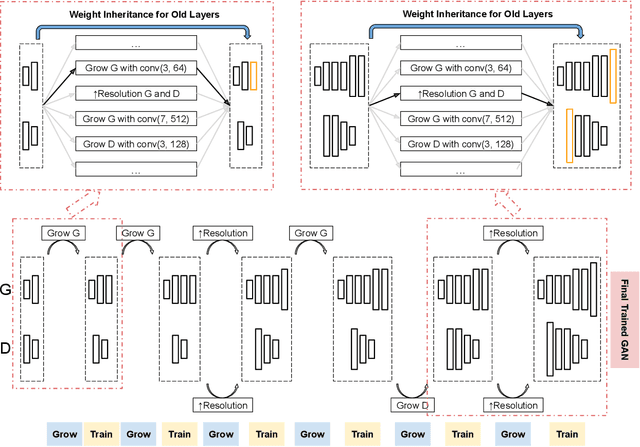



Recent work introduced progressive network growing as a promising way to ease the training for large GANs, but the model design and architecture-growing strategy still remain under-explored and needs manual design for different image data. In this paper, we propose a method to dynamically grow a GAN during training, optimizing the network architecture and its parameters together with automation. The method embeds architecture search techniques as an interleaving step with gradient-based training to periodically seek the optimal architecture-growing strategy for the generator and discriminator. It enjoys the benefits of both eased training because of progressive growing and improved performance because of broader architecture design space. Experimental results demonstrate new state-of-the-art of image generation. Observations in the search procedure also provide constructive insights into the GAN model design such as generator-discriminator balance and convolutional layer choices.
A Unified Framework of Surrogate Loss by Refactoring and Interpolation
Jul 27, 2020



We introduce UniLoss, a unified framework to generate surrogate losses for training deep networks with gradient descent, reducing the amount of manual design of task-specific surrogate losses. Our key observation is that in many cases, evaluating a model with a performance metric on a batch of examples can be refactored into four steps: from input to real-valued scores, from scores to comparisons of pairs of scores, from comparisons to binary variables, and from binary variables to the final performance metric. Using this refactoring we generate differentiable approximations for each non-differentiable step through interpolation. Using UniLoss, we can optimize for different tasks and metrics using one unified framework, achieving comparable performance compared with task-specific losses. We validate the effectiveness of UniLoss on three tasks and four datasets. Code is available at https://github.com/princeton-vl/uniloss.
Generative Modeling for Small-Data Object Detection
Oct 16, 2019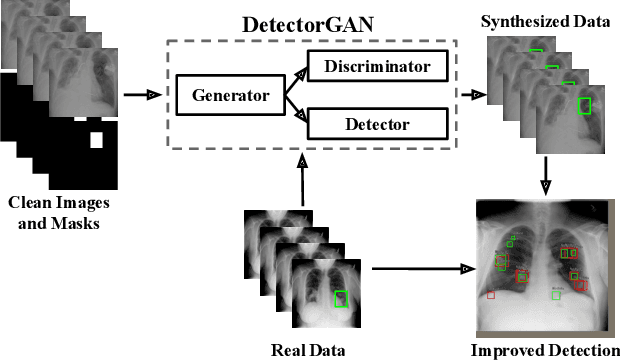

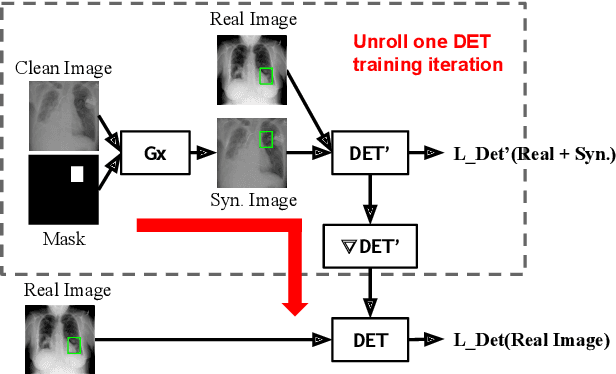

This paper explores object detection in the small data regime, where only a limited number of annotated bounding boxes are available due to data rarity and annotation expense. This is a common challenge today with machine learning being applied to many new tasks where obtaining training data is more challenging, e.g. in medical images with rare diseases that doctors sometimes only see once in their life-time. In this work we explore this problem from a generative modeling perspective by learning to generate new images with associated bounding boxes, and using these for training an object detector. We show that simply training previously proposed generative models does not yield satisfactory performance due to them optimizing for image realism rather than object detection accuracy. To this end we develop a new model with a novel unrolling mechanism that jointly optimizes the generative model and a detector such that the generated images improve the performance of the detector. We show this method outperforms the state of the art on two challenging datasets, disease detection and small data pedestrian detection, improving the average precision on NIH Chest X-ray by a relative 20% and localization accuracy by a relative 50%.
Dynamic Deep Neural Networks: Optimizing Accuracy-Efficiency Trade-offs by Selective Execution
Mar 05, 2018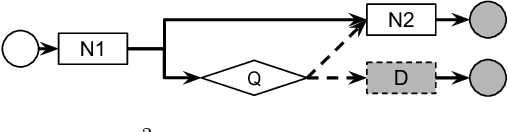

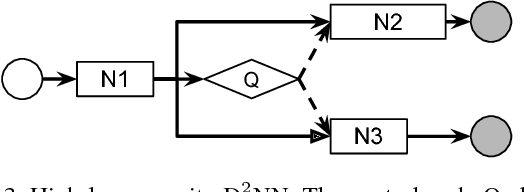
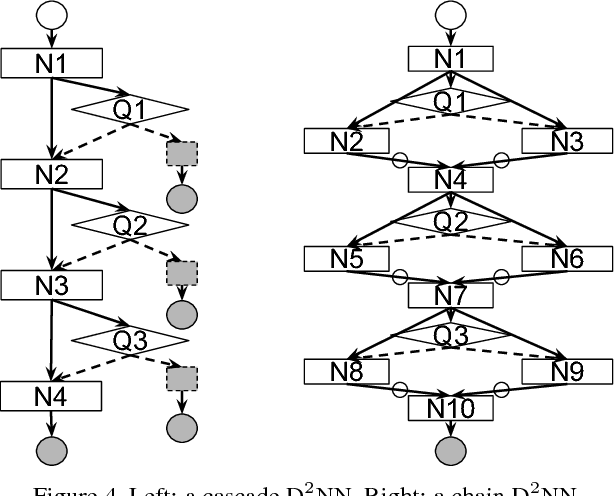
We introduce Dynamic Deep Neural Networks (D2NN), a new type of feed-forward deep neural network that allows selective execution. Given an input, only a subset of D2NN neurons are executed, and the particular subset is determined by the D2NN itself. By pruning unnecessary computation depending on input, D2NNs provide a way to improve computational efficiency. To achieve dynamic selective execution, a D2NN augments a feed-forward deep neural network (directed acyclic graph of differentiable modules) with controller modules. Each controller module is a sub-network whose output is a decision that controls whether other modules can execute. A D2NN is trained end to end. Both regular and controller modules in a D2NN are learnable and are jointly trained to optimize both accuracy and efficiency. Such training is achieved by integrating backpropagation with reinforcement learning. With extensive experiments of various D2NN architectures on image classification tasks, we demonstrate that D2NNs are general and flexible, and can effectively optimize accuracy-efficiency trade-offs.