 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Your Dermatology Classifier Know What It Doesn't Know? Detecting the Long-Tail of Unseen Conditions
Apr 08, 2021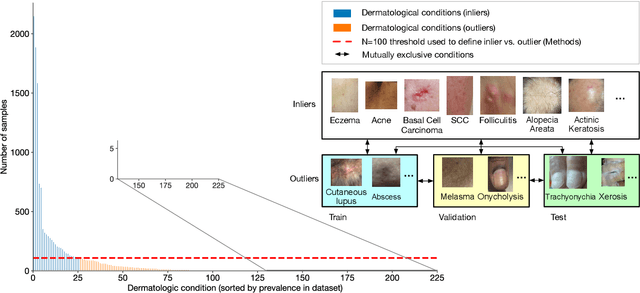
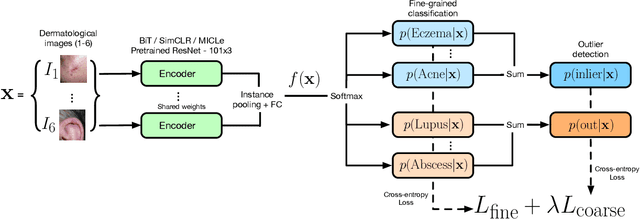
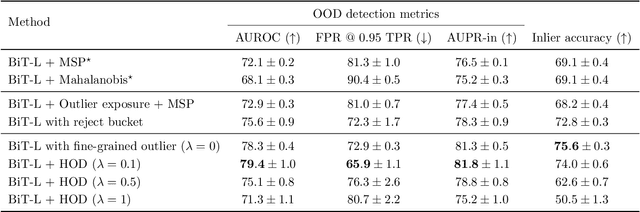
We develop and rigorously evaluate a deep learning based system that can accurately classify skin conditions while detecting rare conditions for which there is not enough data available for training a confident classifier. We frame this task as an out-of-distribution (OOD) detection problem. Our novel approach, hierarchical outlier detection (HOD) assigns multiple abstention classes for each training outlier class and jointly performs a coarse classification of inliers vs. outliers, along with fine-grained classification of the individual classes. We demonstrate the effectiveness of the HOD loss in conjunction with modern representation learning approaches (BiT, SimCLR, MICLe) and explore different ensembling strategies for further improving the results. We perform an extensive subgroup analysis over conditions of varying risk levels and different skin types to investigate how the OOD detection performance changes over each subgroup and demonstrate the gains of our framework in comparison to baselines. Finally, we introduce a cost metric to approximate downstream clinical impact. We use this cost metric to compare the proposed method against a baseline system, thereby making a stronger case for the overall system effectiveness in a real-world deployment scenario.
Let's Transfer Transformations of Shared Semantic Representations
Mar 02, 2019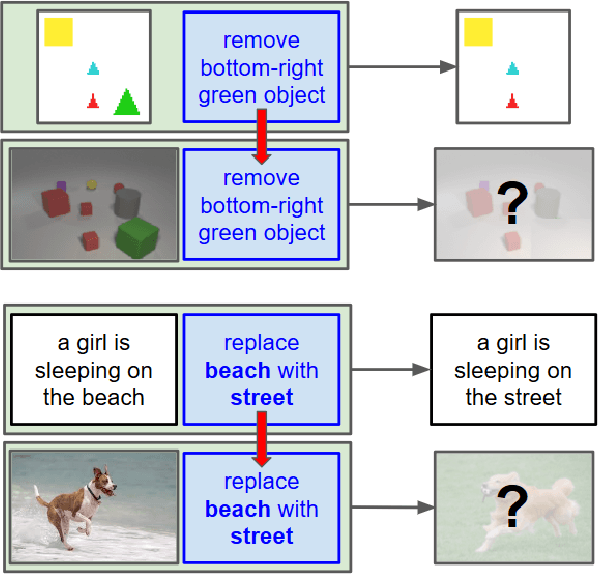

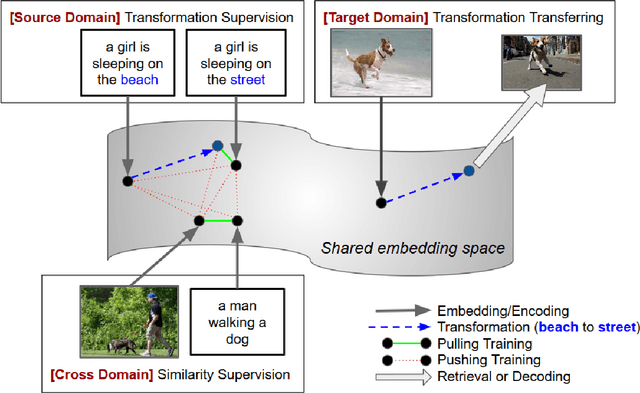

With a good image understanding capability, can we manipulate the images high level semantic representation? Such transformation operation can be used to generate or retrieve similar images but with a desired modification (for example changing beach background to street background); similar ability has been demonstrated in zero shot learning, attribute composition and attribute manipulation image search. In this work we show how one can learn transformations with no training examples by learning them on another domain and then transfer to the target domain. This is feasible if: first, transformation training data is more accessible in the other domain and second, both domains share similar semantics such that one can learn transformations in a shared embedding space. We demonstrate this on an image retrieval task where search query is an image, plus an additional transformation specification (for example: search for images similar to this one but background is a street instead of a beach). In one experiment, we transfer transformation from synthesized 2D blobs image to 3D rendered image, and in the other, we transfer from text domain to natural image domain.
Composing Text and Image for Image Retrieval - An Empirical Odyssey
Dec 18, 2018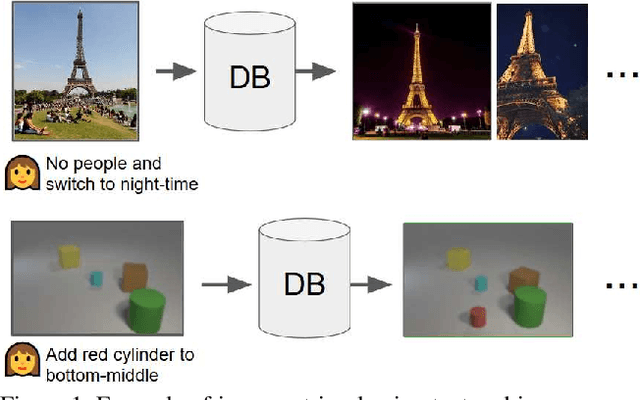
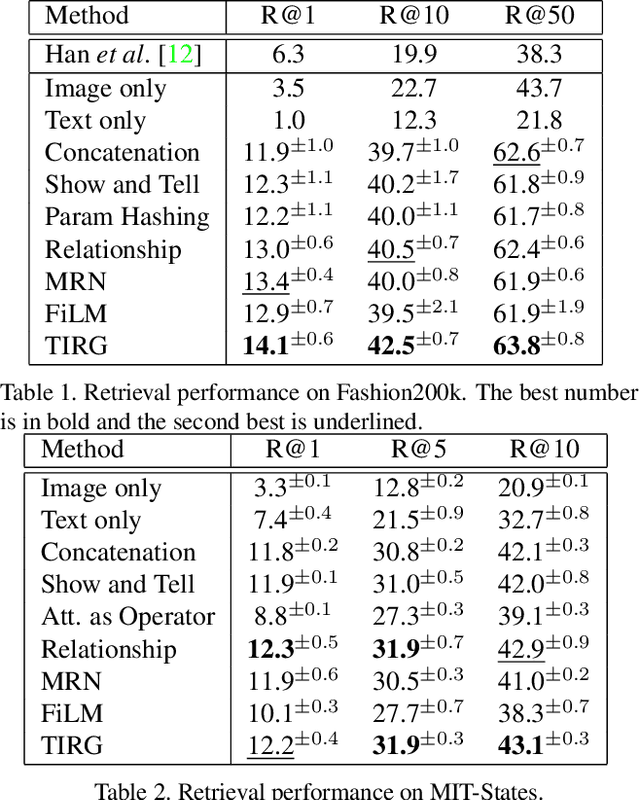
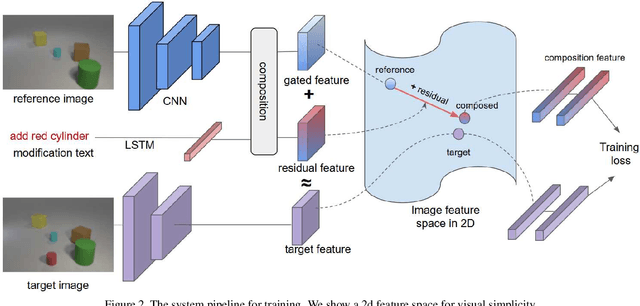

In this paper, we study the task of image retrieval, where the input query is specified in the form of an image plus some text that describes desired modifications to the input image. For example, we may present an image of the Eiffel tower, and ask the system to find images which are visually similar but are modified in small ways, such as being taken at nighttime instead of during the day. To tackle this task, we learn a similarity metric between a target image and a source image plus source text, an embedding and composing function such that target image feature is close to the source image plus text composition feature. We propose a new way to combine image and text using such function that is designed for the retrieval task. We show this outperforms existing approaches on 3 different datasets, namely Fashion-200k, MIT-States and a new synthetic dataset we create based on CLEVR. We also show that our approach can be used to classify input queries, in addition to image retrieval.
Generalization in Metric Learning: Should the Embedding Layer be the Embedding Layer?
Mar 08, 2018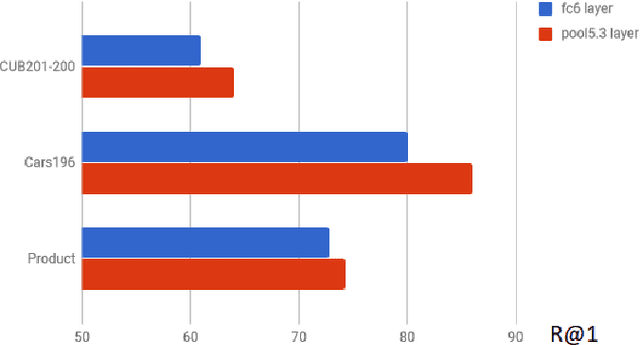

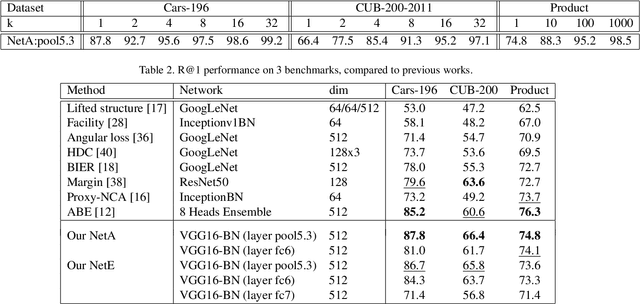
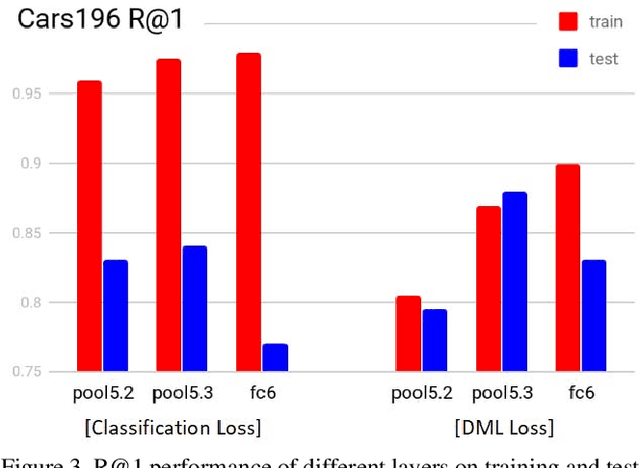
Many recent works advancing deep learning tend to focus on large scale setting with the goal of more effective training and better fitting. This goal might be less applicable to the case of small to medium scale. Studying deep metric learning under such setting, we reason that better generalization could be a big contributing factor to improvement of previous works, as well as the goal for further improvement. We investigate using other layers in a deep metric learning system (beside the embedding layer) for feature extraction and analyze how well they perform on training data and generalize to testing data. From this study, we suggest a new regularization practice and demonstrate state-of-the-art performance on 3 fine-grained image retrieval benchmarks: Cars-196, CUB-200-2011 and Stanford Online Product.
Revisiting IM2GPS in the Deep Learning Era
May 13, 2017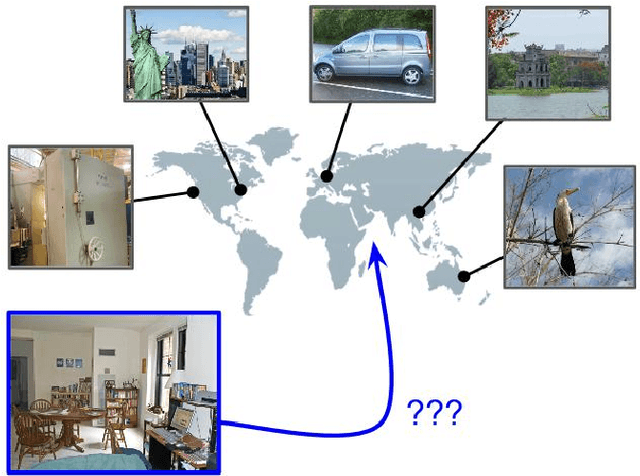
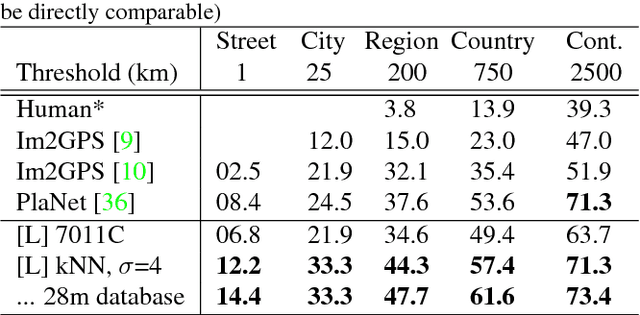

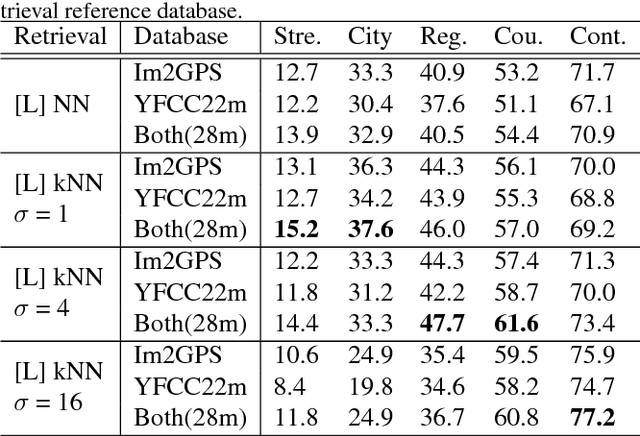
Image geolocalization, inferring the geographic location of an image, is a challenging computer vision problem with many potential applications. The recent state-of-the-art approach to this problem is a deep image classification approach in which the world is spatially divided into cells and a deep network is trained to predict the correct cell for a given image. We propose to combine this approach with the original Im2GPS approach in which a query image is matched against a database of geotagged images and the location is inferred from the retrieved set. We estimate the geographic location of a query image by applying kernel density estimation to the locations of its nearest neighbors in the reference database. Interestingly, we find that the best features for our retrieval task are derived from networks trained with classification loss even though we do not use a classification approach at test time. Training with classification loss outperforms several deep feature learning methods (e.g. Siamese networks with contrastive of triplet loss) more typical for retrieval applications. Our simple approach achieves state-of-the-art geolocalization accuracy while also requiring significantly less training data.
Localizing and Orienting Street Views Using Overhead Imagery
Mar 22, 2017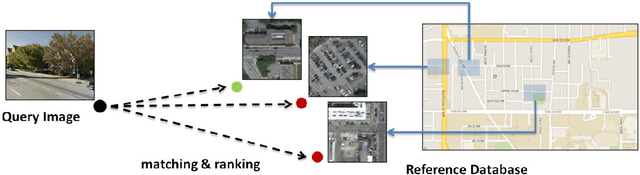
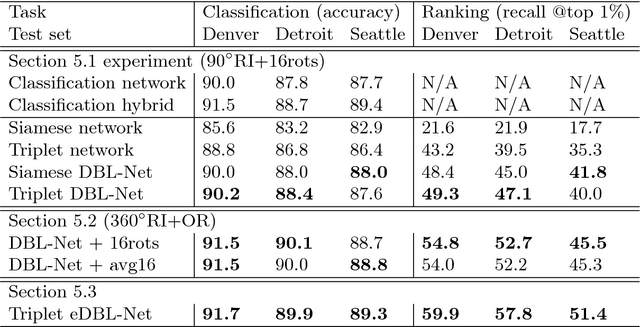


In this paper we aim to determine the location and orientation of a ground-level query image by matching to a reference database of overhead (e.g. satellite) images. For this task we collect a new dataset with one million pairs of street view and overhead images sampled from eleven U.S. cities. We explore several deep CNN architectures for cross-domain matching -- Classification, Hybrid, Siamese, and Triplet networks. Classification and Hybrid architectures are accurate but slow since they allow only partial feature precomputation. We propose a new loss function which significantly improves the accuracy of Siamese and Triplet embedding networks while maintaining their applicability to large-scale retrieval tasks like image geolocalization. This image matching task is challenging not just because of the dramatic viewpoint difference between ground-level and overhead imagery but because the orientation (i.e. azimuth) of the street views is unknown making correspondence even more difficult. We examine several mechanisms to match in spite of this -- training for rotation invariance, sampling possible rotations at query time, and explicitly predicting relative rotation of ground and overhead images with our deep networks. It turns out that explicit orientation supervision also improves location prediction accuracy. Our best performing architectures are roughly 2.5 times as accurate as the commonly used Siamese network baseline.