 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing and Orienting Street Views Using Overhead Imagery
Paper and Code
Mar 22, 2017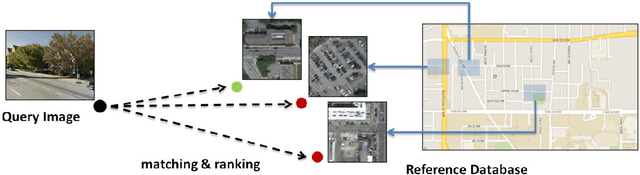
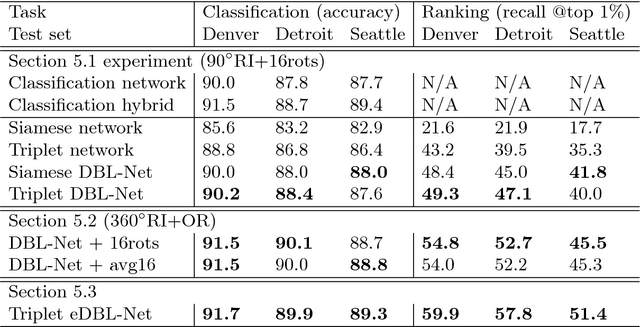


In this paper we aim to determine the location and orientation of a ground-level query image by matching to a reference database of overhead (e.g. satellite) images. For this task we collect a new dataset with one million pairs of street view and overhead images sampled from eleven U.S. cities. We explore several deep CNN architectures for cross-domain matching -- Classification, Hybrid, Siamese, and Triplet networks. Classification and Hybrid architectures are accurate but slow since they allow only partial feature precomputation. We propose a new loss function which significantly improves the accuracy of Siamese and Triplet embedding networks while maintaining their applicability to large-scale retrieval tasks like image geolocalization. This image matching task is challenging not just because of the dramatic viewpoint difference between ground-level and overhead imagery but because the orientation (i.e. azimuth) of the street views is unknown making correspondence even more difficult. We examine several mechanisms to match in spite of this -- training for rotation invariance, sampling possible rotations at query time, and explicitly predicting relative rotation of ground and overhead images with our deep networks. It turns out that explicit orientation supervision also improves location prediction accuracy. Our best performing architectures are roughly 2.5 times as accurate as the commonly used Siamese network baseline.