 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in Metric Learning: Should the Embedding Layer be the Embedding Layer?
Paper and Code
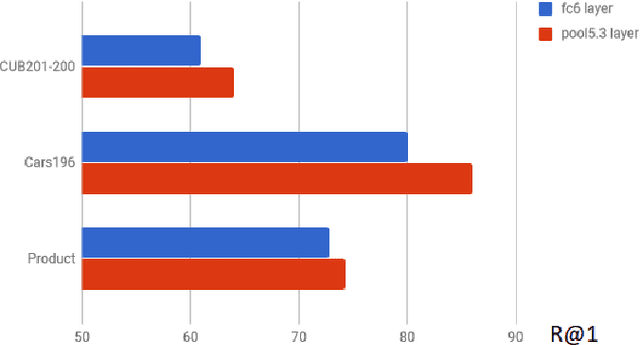

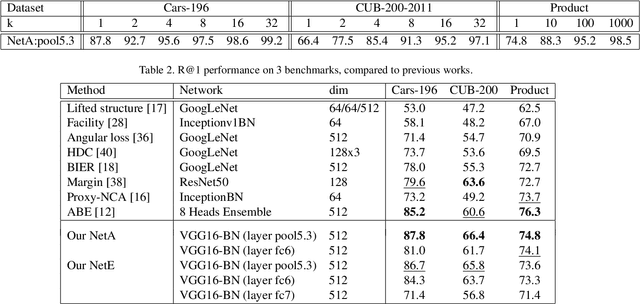
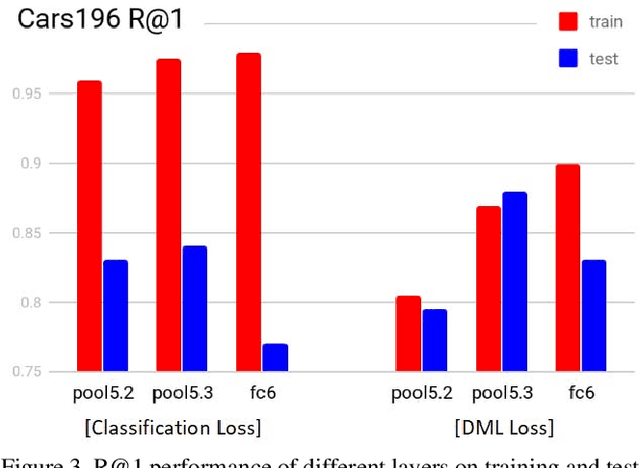
Many recent works advancing deep learning tend to focus on large scale setting with the goal of more effective training and better fitting. This goal might be less applicable to the case of small to medium scale. Studying deep metric learning under such setting, we reason that better generalization could be a big contributing factor to improvement of previous works, as well as the goal for further improvement. We investigate using other layers in a deep metric learning system (beside the embedding layer) for feature extraction and analyze how well they perform on training data and generalize to testing data. From this study, we suggest a new regularization practice and demonstrate state-of-the-art performance on 3 fine-grained image retrieval benchmarks: Cars-196, CUB-200-2011 and Stanford Online Product.