 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICSVR: Investigating Compositional and Semantic Understanding in Video Retrieval Models
Paper and Code
Jun 28, 2023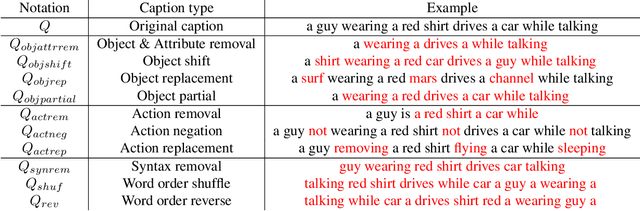
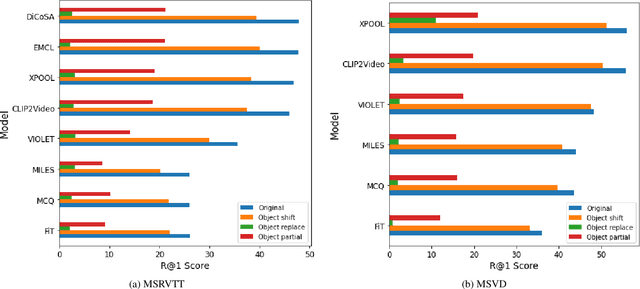
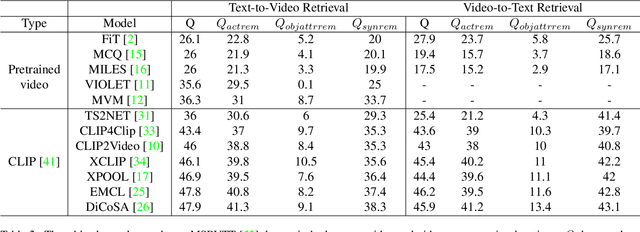
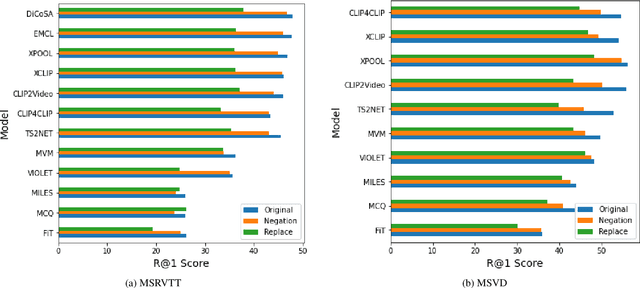
Video retrieval (VR) involves retrieving the ground truth video from the video database given a text caption or vice-versa. The two important components of compositionality: objects \& attributes and actions are joined using correct semantics to form a proper text query. These components (objects \& attributes, actions and semantics) each play an important role to help distinguish among videos and retrieve the correct ground truth video. However, it is unclear what is the effect of these components on the video retrieval performance. We therefore, conduct a systematic study to evaluate the compositional and semantic understanding of video retrieval models on standard benchmarks such as MSRVTT, MSVD and DIDEMO. The study is performed on two categories of video retrieval models: (i) which are pre-trained on video-text pairs and fine-tuned on downstream video retrieval datasets (Eg. Frozen-in-Time, Violet, MCQ etc.) (ii) which adapt pre-trained image-text representations like CLIP for video retrieval (Eg. CLIP4Clip, XCLIP, CLIP2Video etc.). Our experiments reveal that actions and semantics play a minor role compared to objects \& attributes in video understanding. Moreover, video retrieval models that use pre-trained image-text representations (CLIP) have better semantic and compositional understanding as compared to models pre-trained on video-text data.