 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasures of classification bias derived from sample size analysis
Jan 06, 2026We propose the use of a simple intuitive principle for measuring algorithmic classification bias: the significance of the differences in a classifier's error rates across the various demographics is inversely commensurate with the sample size required to statistically detect them. That is, if large sample sizes are required to statistically establish biased behavior, the algorithm is less biased, and vice versa. In a simple setting, we assume two distinct demographics, and non-parametric estimates of the error rates on them, e1 and e2, respectively. We use a well-known approximate formula for the sample size of the chi-squared test, and verify some basic desirable properties of the proposed measure. Next, we compare the proposed measure with two other commonly used statistics, the difference e2-e1 and the ratio e2/e1 of the error rates. We establish that the proposed measure is essentially different in that it can rank algorithms for bias differently, and we discuss some of its advantages over the other two measures. Finally, we briefly discuss how some of the desirable properties of the proposed measure emanate from fundamental characteristics of the method, rather than the approximate sample size formula we used, and thus, are expected to hold in more complex settings with more than two demographics.
Zero-failure testing of binary classifiers
Jul 04, 2024



We propose using performance metrics derived from zero-failure testing to assess binary classifiers. The principal characteristic of the proposed approach is the asymmetric treatment of the two types of error. In particular, we construct a test set consisting of positive and negative samples, set the operating point of the binary classifier at the lowest value that will result to correct classifications of all positive samples, and use the algorithm's success rate on the negative samples as a performance measure. A property of the proposed approach, setting it apart from other commonly used testing methods, is that it allows the construction of a series of tests of increasing difficulty, corresponding to a nested sequence of positive sample test sets. We illustrate the proposed method on the problem of age estimation for determining whether a subject is above a legal age threshold, a problem that exemplifies the asymmetry of the two types of error. Indeed, misclassifying an under-aged subject is a legal and regulatory issue, while misclassifications of people above the legal age is an efficiency issue primarily concerning the commercial user of the age estimation system.
Race Bias Analysis of Bona Fide Errors in face anti-spoofing
Oct 11, 2022



The study of bias in Machine Learning is receiving a lot of attention in recent years, however, few only papers deal explicitly with the problem of race bias in face anti-spoofing. In this paper, we present a systematic study of race bias in face anti-spoofing with three key characteristics: the focus is on analysing potential bias in the bona fide errors, where significant ethical and legal issues lie; the analysis is not restricted to the final binary outcomes of the classifier, but also covers the classifier's scalar responses and its latent space; the threshold determining the operating point of the classifier is considered a variable. We demonstrate the proposed bias analysis process on a VQ-VAE based face anti-spoofing algorithm, trained on the Replay Attack and the Spoof in the Wild (SiW) databases, and analysed for bias on the SiW and Racial Faces in the Wild (RFW), databases. The results demonstrate that race bias is not necessarily the result of different mean response values among the various populations. Instead, it can be better understood as the combined effect of several possible characteristics of the response distributions: different means; different variances; bimodal behaviour; existence of outliers.
Use of in-the-wild images for anomaly detection in face anti-spoofing
Jun 18, 2020
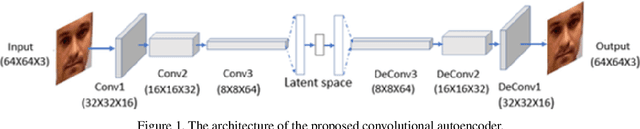
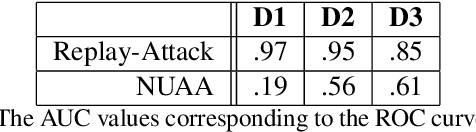
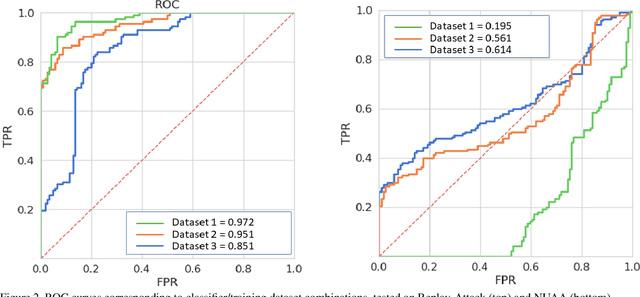
The traditional approach to face anti-spoofing sees it as a binary classification problem, and binary classifiers are trained and validated on specialized anti-spoofing databases. One of the drawbacks of this approach is that, due to the variability of face spoofing attacks, environmental factors, and the typically small sample size, such classifiers do not generalize well to previously unseen databases. Anomaly detection, which approaches face anti-spoofing as a one-class classification problem, is emerging as an increasingly popular alternative approach. Nevertheless, in all existing work on anomaly detection for face anti-spoofing, the proposed training protocols utilize images from specialized anti-spoofing databases only, even though only common images of real faces are needed. Here, we explore the use of in-the-wild images, and images from non-specialized face databases, to train one-class classifiers for face anti-spoofing. Employing a well-established technique, we train a convolutional autoencoder on real faces and compare the reconstruction error of the input against a threshold to classify a face image accordingly as either client or imposter. Our results show that the inclusion in the training set of in-the-wild images increases the discriminating power of the classifier significantly on an unseen database, as evidenced by a large increase in the value of the Area Under the Curve. In a limitation of our approach, we note that the problem of finding a suitable operating point on the unseen database remains a challenge, as evidenced by the values of the Half Total Error Rate.
A study of the effect of the illumination model on the generation of synthetic training datasets
Jun 15, 2020


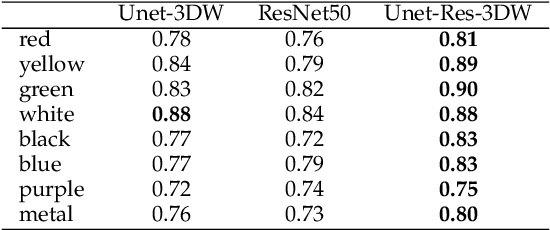
The use of computer generated images to train Deep Neural Networks is a viable alternative to real images when the latter are scarce or expensive. In this paper, we study how the illumination model used by the rendering software affects the quality of the generated images. We created eight training sets, each one with a different illumination model, and tested them on three different network architectures, ResNet, U-Net and a combined architecture developed by us. The test set consisted of photos of 3D printed objects produced from the same CAD models used to generate the training set. The effect of the other parameters of the rendering process, such as textures and camera position, was randomized. Our results show that the effect of the illumination model is important, comparable in significance to the network architecture. We also show that both light probes capturing natural environmental light, and modelled lighting environments, can give good results. In the case of light probes, we identified as two significant factors affecting performance the similarity between the light probe and the test environment, as well as the light probe's resolution. Regarding modelled lighting environment, similarity with the test environment was again identified as a significant factor.
Using theoretical ROC curves for analysing machine learning binary classifiers
Sep 21, 2019

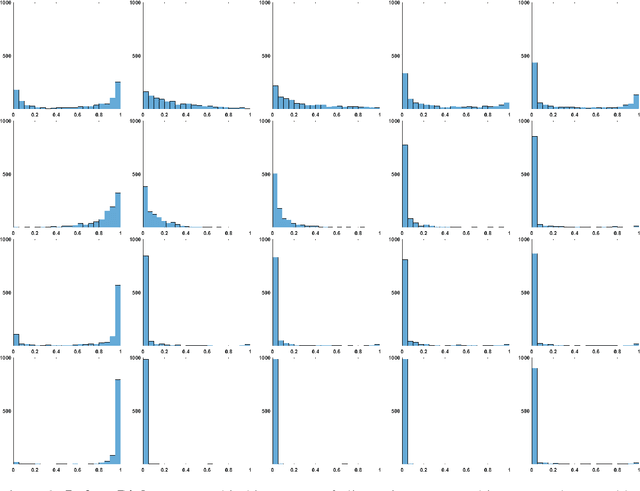

Most binary classifiers work by processing the input to produce a scalar response and comparing it to a threshold value. The various measures of classifier performance assume, explicitly or implicitly, probability distributions $P_s$ and $P_n$ of the response belonging to either class, probability distributions for the cost of each type of misclassification, and compute a performance score from the expected cost. In machine learning, classifier responses are obtained experimentally and performance scores are computed directly from them, without any assumptions on $P_s$ and $P_n$. Here, we argue that the omitted step of estimating theoretical distributions for $P_s$ and $P_n$ can be useful. In a biometric security example, we fit beta distributions to the responses of two classifiers, one based on logistic regression and one on ANNs, and use them to establish a categorisation into a small number of classes with different extremal behaviours at the ends of the ROC curves.
Watermark retrieval from 3D printed objects via synthetic data training
May 23, 2019
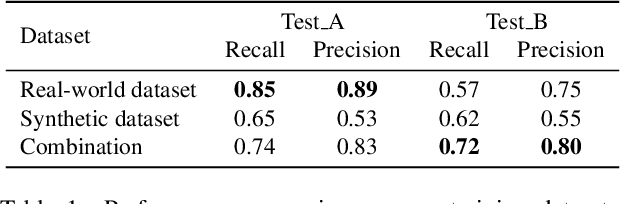
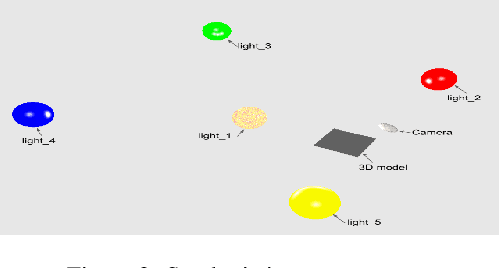
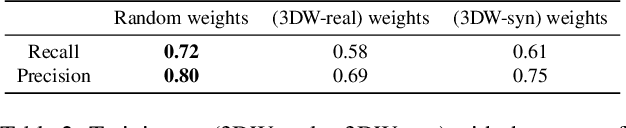
We present a deep neural network based method for the retrieval of watermarks from images of 3D printed objects. To deal with the variability of all possible 3D printing and image acquisition settings we train the network with synthetic data. The main simulator parameters such as texture, illumination and camera position are dynamically randomized in non-realistic ways, forcing the neural network to learn the intrinsic features of the 3D printed watermarks. At the end of the pipeline, the watermark, in the form of a two-dimensional bit array, is retrieved through a series of simple image processing and statistical operations applied on the confidence map generated by the neural network. The results demonstrate that the inclusion of synthetic DR data in the training set increases the generalization power of the network, which performs better on images from previously unseen 3D printed objects. We conclude that in our application domain of information retrieval from 3D printed objects, where access to the exact CAD files of the printed objects can be assumed, one can use inexpensive synthetic data to enhance neural network training, reducing the need for the labour intensive process of creating large amounts of hand labelled real data or the need to generate photorealistic synthetic data.
Watermark Retrieval from 3D Printed Objects via Convolutional Neural Networks
Nov 19, 2018
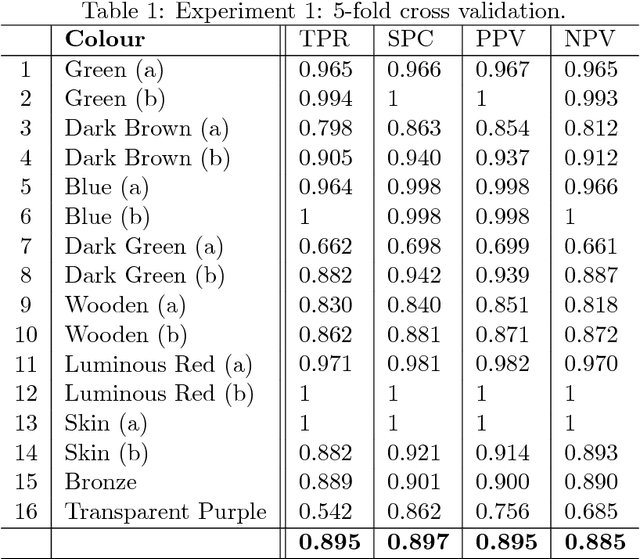


We present a method for reading digital data embedded in planar 3D printed surfaces. The data are organised in binary arrays and embedded as surface textures in a way inspired by QR codes. At the core of the retrieval method lies a Convolutional Neural Network, outputting a confidence map of the location of the surface textures encoding value 1 bits. Subsequently, the bit array is retrieved through a series of simple image processing and statistical operations applied on the confidence map. Extensive experimentation with images captured from various camera views, under various illumination conditions and from objects printed with various material colours, shows that the proposed method generalizes well and achieves the level of accuracy required in practical applications.