 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Interpretable End-to-End Vision-Based Motion Planning for Autonomous Driving with Optical Flow Distillation
Paper and Code
Apr 18, 2021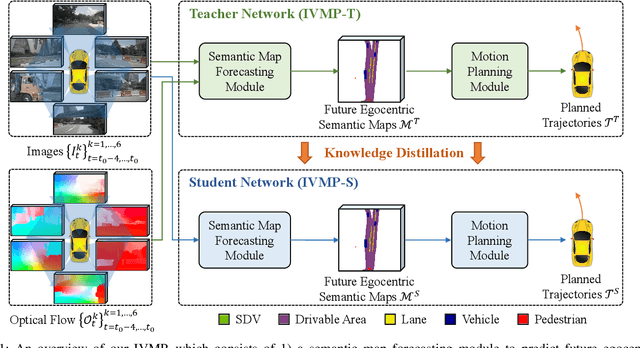
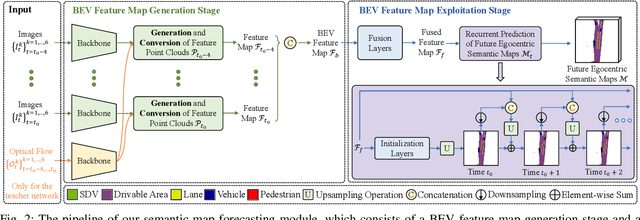

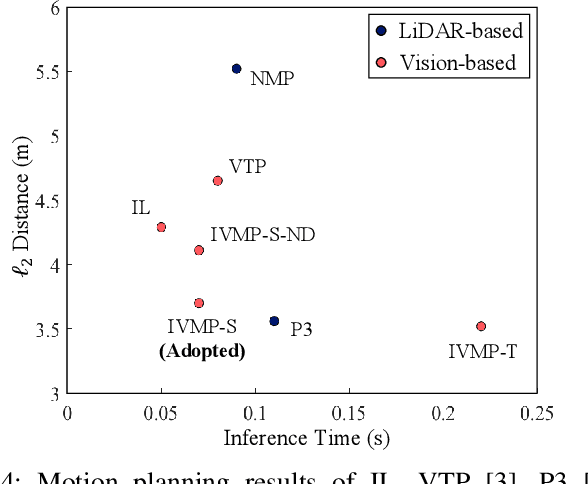
Recently, deep-learning based approaches have achieved impressive performance for autonomous driving. However, end-to-end vision-based methods typically have limited interpretability, making the behaviors of the deep networks difficult to explain. Hence, their potential applications could be limited in practice. To address this problem, we propose an interpretable end-to-end vision-based motion planning approach for autonomous driving, referred to as IVMP. Given a set of past surrounding-view images, our IVMP first predicts future egocentric semantic maps in bird's-eye-view space, which are then employed to plan trajectories for self-driving vehicles. The predicted future semantic maps not only provide useful interpretable information, but also allow our motion planning module to handle objects with low probability, thus improving the safety of autonomous driving. Moreover, we also develop an optical flow distillation paradigm, which can effectively enhance the network while still maintaining its real-time performance. Extensive experiments on the nuScenes dataset and closed-loop simulation show that our IVMP significantly outperforms the state-of-the-art approaches in imitating human drivers with a much higher success rate. Our project page is available at https://sites.google.com/view/ivmp.