 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRareBench: Can LLMs Serve as Rare Diseases Specialists?
Feb 09, 2024



Generalist Large Language Models (LLMs), such as GPT-4, have shown considerable promise in various domains, including medical diagnosis. Rare diseases, affecting approximately 300 million people worldwide, often have unsatisfactory clinical diagnosis rates primarily due to a lack of experienced physicians and the complexity of differentiating among many rare diseases. In this context, recent news such as "ChatGPT correctly diagnosed a 4-year-old's rare disease after 17 doctors failed" underscore LLMs' potential, yet underexplored, role in clinically diagnosing rare diseases. To bridge this research gap, we introduce RareBench, a pioneering benchmark designed to systematically evaluate the capabilities of LLMs on 4 critical dimensions within the realm of rare diseases. Meanwhile, we have compiled the largest open-source dataset on rare disease patients, establishing a benchmark for future studies in this domain. To facilitate differential diagnosis of rare diseases, we develop a dynamic few-shot prompt methodology, leveraging a comprehensive rare disease knowledge graph synthesized from multiple knowledge bases, significantly enhancing LLMs' diagnostic performance. Moreover, we present an exhaustive comparative study of GPT-4's diagnostic capabilities against those of specialist physicians. Our experimental findings underscore the promising potential of integrating LLMs into the clinical diagnostic process for rare diseases. This paves the way for exciting possibilities in future advancements in this field.
Regret Analysis for Hierarchical Experts Bandit Problem
Aug 11, 2022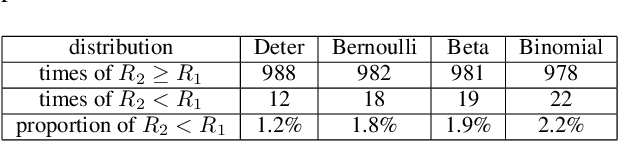

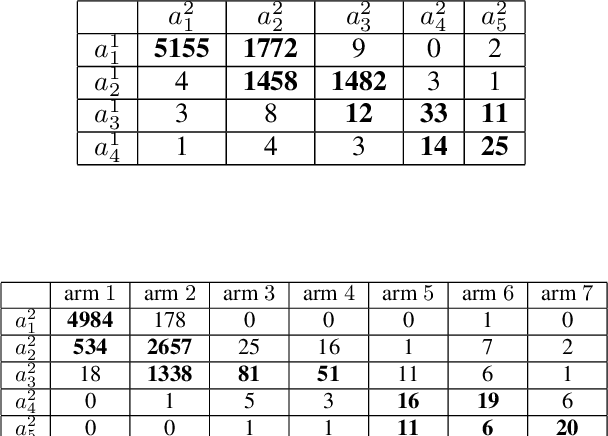

We study an extension of standard bandit problem in which there are R layers of experts. Multi-layered experts make selections layer by layer and only the experts in the last layer can play arms. The goal of the learning policy is to minimize the total regret in this hierarchical experts setting. We first analyze the case that total regret grows linearly with the number of layers. Then we focus on the case that all experts are playing Upper Confidence Bound (UCB) strategy and give several sub-linear upper bounds for different circumstances. Finally, we design some experiments to help the regret analysis for the general case of hierarchical UCB structure and show the practical significance of our theoretical results. This article gives many insights about reasonable hierarchical decision structure.
NAST: A Non-Autoregressive Generator with Word Alignment for Unsupervised Text Style Transfer
Jun 04, 2021
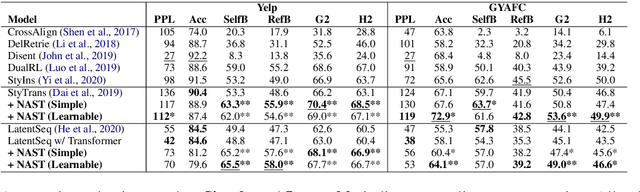
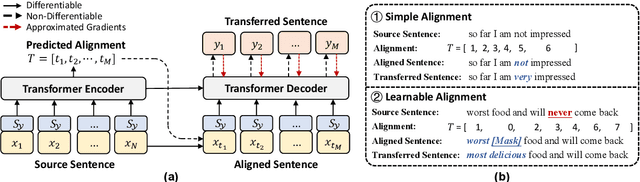
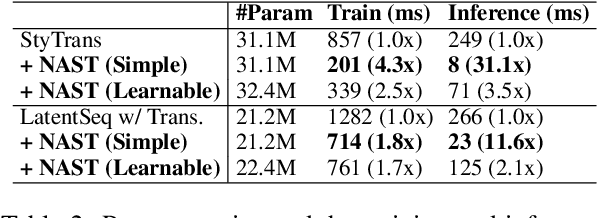
Autoregressive models have been widely used in unsupervised text style transfer. Despite their success, these models still suffer from the content preservation problem that they usually ignore part of the source sentence and generate some irrelevant words with strong styles. In this paper, we propose a Non-Autoregressive generator for unsupervised text Style Transfer (NAST), which alleviates the problem from two aspects. First, we observe that most words in the transferred sentence can be aligned with related words in the source sentence, so we explicitly model word alignments to suppress irrelevant words. Second, existing models trained with the cycle loss align sentences in two stylistic text spaces, which lacks fine-grained control at the word level. The proposed non-autoregressive generator focuses on the connections between aligned words, which learns the word-level transfer between styles. For experiments, we integrate the proposed generator into two base models and evaluate them on two style transfer tasks. The results show that NAST can significantly improve the overall performance and provide explainable word alignments. Moreover, the non-autoregressive generator achieves over 10x speedups at inference. Our codes are available at https://github.com/thu-coai/NAST.