 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised learning of site percolation based on shuffled configurations
Nov 20, 2023



In the field of statistical physics, machine learning has gained significant popularity and has achieved remarkable results in recent studies on phase transitions.In this paper, we apply Principal Component Analysis (PCA) and Autoencoder(AE) based on Unsupervised learning to study the various configurations of the percolation model in equilibrium phase transition. In certain phase transition models, such as the DP model in non-equilibrium phase transitions, the order parameter is particle density. However, in some other phase transition models, such as the percolation model, it is not. This study involved randomizing and selecting percolation graphs to be used as input for a neural network, and analyzed the obtained results, indicating that the outputs of the single latent variable of AE and the first principal component of PCA are signals related to particle density.
Transfer learning of phase transitions in percolation and directed percolation
Jan 06, 2022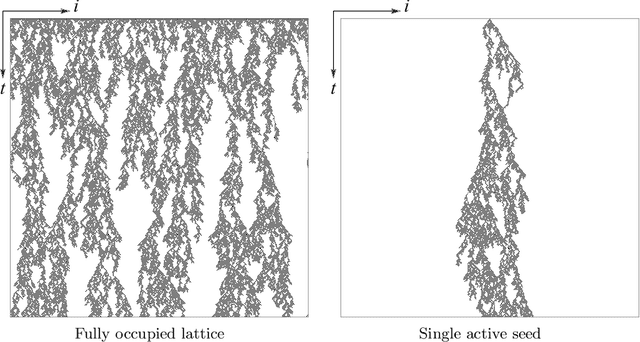
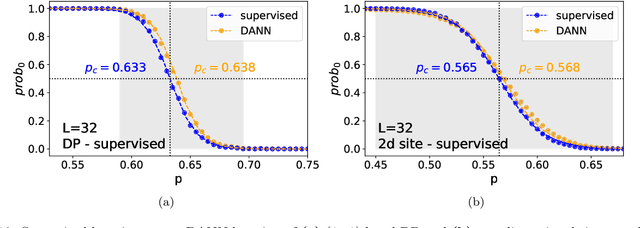

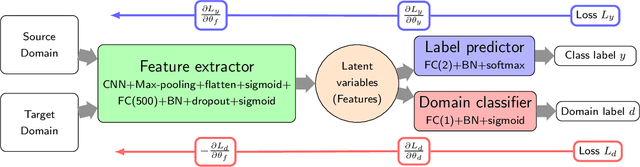
The latest advances of statistical physics have shown remarkable performance of machine learning in identifying phase transitions. In this paper, we apply domain adversarial neural network (DANN) based on transfer learning to studying non-equilibrium and equilibrium phase transition models, which are percolation model and directed percolation (DP) model, respectively. With the DANN, only a small fraction of input configurations (2d images) needs to be labeled, which is automatically chosen, in order to capture the critical point. To learn the DP model, the method is refined by an iterative procedure in determining the critical point, which is a prerequisite for the data collapse in calculating the critical exponent $\nu_{\perp}$. We then apply the DANN to a two-dimensional site percolation with configurations filtered to include only the largest cluster which may contain the information related to the order parameter. The DANN learning of both models yields reliable results which are comparable to the ones from Monte Carlo simulations. Our study also shows that the DANN can achieve quite high accuracy at much lower cost, compared to the supervised learning.
Vis-TOP: Visual Transformer Overlay Processor
Oct 21, 2021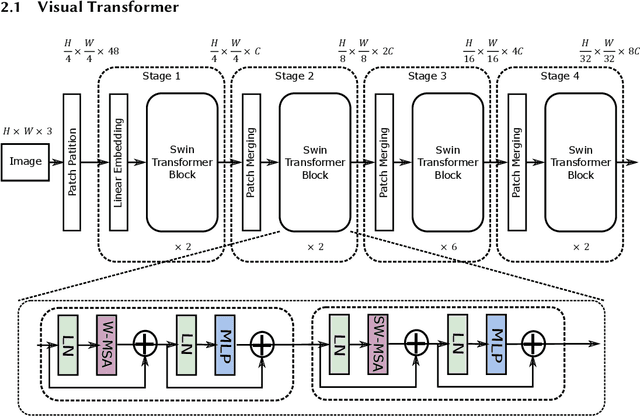

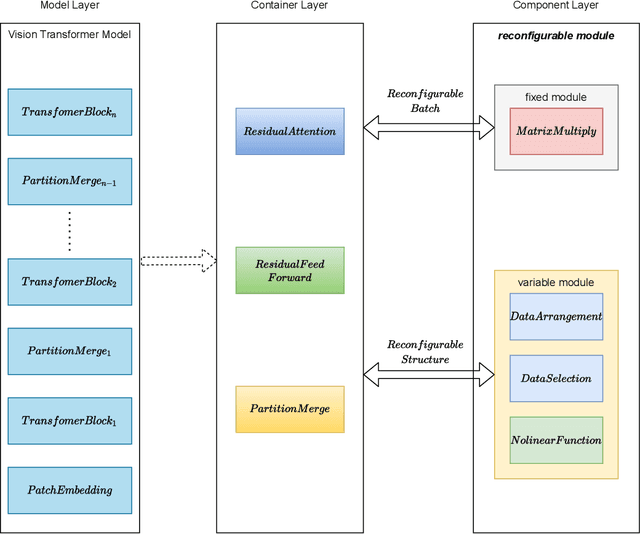
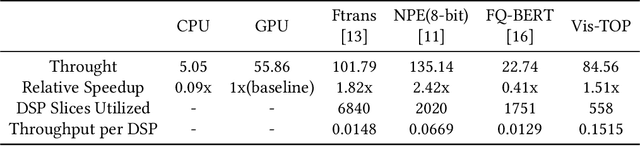
In recent years, Transformer has achieved good results in Natural Language Processing (NLP) and has also started to expand into Computer Vision (CV). Excellent models such as the Vision Transformer and Swin Transformer have emerged. At the same time, the platform for Transformer models was extended to embedded devices to meet some resource-sensitive application scenarios. However, due to the large number of parameters, the complex computational flow and the many different structural variants of Transformer models, there are a number of issues that need to be addressed in its hardware design. This is both an opportunity and a challenge. We propose Vis-TOP (Visual Transformer Overlay Processor), an overlay processor for various visual Transformer models. It differs from coarse-grained overlay processors such as CPU, GPU, NPE, and from fine-grained customized designs for a specific model. Vis-TOP summarizes the characteristics of all visual Transformer models and implements a three-layer and two-level transformation structure that allows the model to be switched or changed freely without changing the hardware architecture. At the same time, the corresponding instruction bundle and hardware architecture are designed in three-layer and two-level transformation structure. After quantization of Swin Transformer tiny model using 8-bit fixed points (fix_8), we implemented an overlay processor on the ZCU102. Compared to GPU, the TOP throughput is 1.5x higher. Compared to the existing Transformer accelerators, our throughput per DSP is between 2.2x and 11.7x higher than others. In a word, the approach in this paper meets the requirements of real-time AI in terms of both resource consumption and inference speed. Vis-TOP provides a cost-effective and power-effective solution based on reconfigurable devices for computer vision at the edge.