 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWelfare and Fairness in Multi-objective Reinforcement Learning
Dec 08, 2022



We study fair multi-objective reinforcement learning in which an agent must learn a policy that simultaneously achieves high reward on multiple dimensions of a vector-valued reward. Motivated by the fair resource allocation literature, we model this as an expected welfare maximization problem, for some non-linear fair welfare function of the vector of long-term cumulative rewards. One canonical example of such a function is the Nash Social Welfare, or geometric mean, the log transform of which is also known as the Proportional Fairness objective. We show that even approximately optimal optimization of the expected Nash Social Welfare is computationally intractable even in the tabular case. Nevertheless, we provide a novel adaptation of Q-learning that combines non-linear scalarized learning updates and non-stationary action selection to learn effective policies for optimizing nonlinear welfare functions. We show that our algorithm is provably convergent, and we demonstrate experimentally that our approach outperforms techniques based on linear scalarization, mixtures of optimal linear scalarizations, or stationary action selection for the Nash Social Welfare Objective.
Vis-TOP: Visual Transformer Overlay Processor
Oct 21, 2021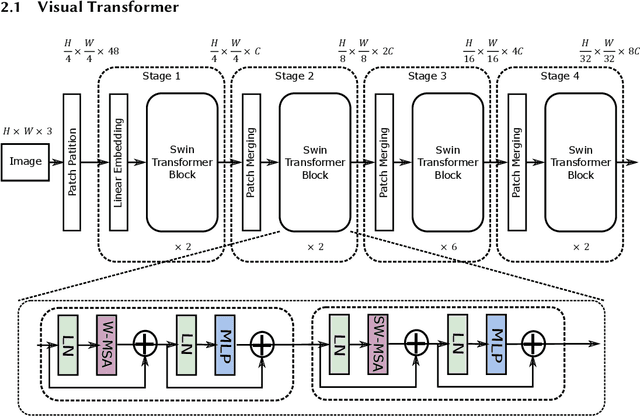

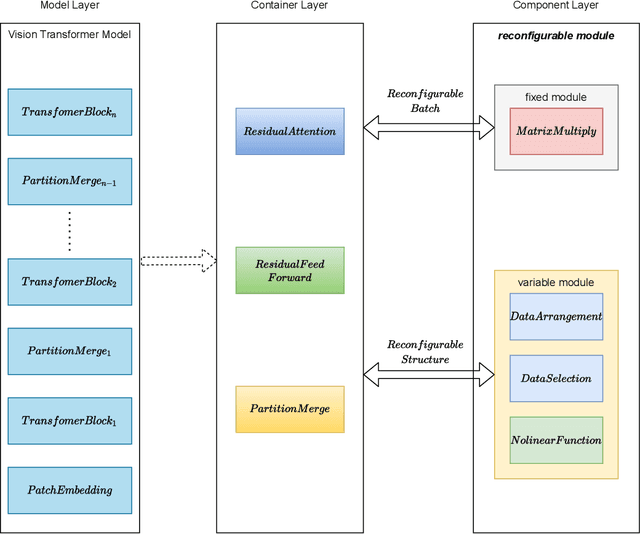
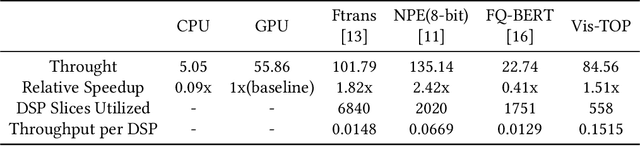
In recent years, Transformer has achieved good results in Natural Language Processing (NLP) and has also started to expand into Computer Vision (CV). Excellent models such as the Vision Transformer and Swin Transformer have emerged. At the same time, the platform for Transformer models was extended to embedded devices to meet some resource-sensitive application scenarios. However, due to the large number of parameters, the complex computational flow and the many different structural variants of Transformer models, there are a number of issues that need to be addressed in its hardware design. This is both an opportunity and a challenge. We propose Vis-TOP (Visual Transformer Overlay Processor), an overlay processor for various visual Transformer models. It differs from coarse-grained overlay processors such as CPU, GPU, NPE, and from fine-grained customized designs for a specific model. Vis-TOP summarizes the characteristics of all visual Transformer models and implements a three-layer and two-level transformation structure that allows the model to be switched or changed freely without changing the hardware architecture. At the same time, the corresponding instruction bundle and hardware architecture are designed in three-layer and two-level transformation structure. After quantization of Swin Transformer tiny model using 8-bit fixed points (fix_8), we implemented an overlay processor on the ZCU102. Compared to GPU, the TOP throughput is 1.5x higher. Compared to the existing Transformer accelerators, our throughput per DSP is between 2.2x and 11.7x higher than others. In a word, the approach in this paper meets the requirements of real-time AI in terms of both resource consumption and inference speed. Vis-TOP provides a cost-effective and power-effective solution based on reconfigurable devices for computer vision at the edge.