 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode as Agent Harness
May 18, 2026Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. We frame this shift through the lens of agent harnesses and introduce code as agent harness: a unified view that centers code as the basis for agent infrastructure. To systematically study this perspective, we organize the survey around three connected layers. First, we study the harness interface, where code connects agents to reasoning, action, and environment modeling. Second, we examine harness mechanisms: planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive. Third, we discuss scaling the harness from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification. Across these layers, we summarize representative methods and practical applications of code as agent harness, spanning coding assistants, GUI/OS automation, embodied agents, scientific discovery, personalization and recommendation, DevOps, and enterprise workflows. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight for safety-critical actions, and extensions to multimodal environments. By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
MC-Search: Evaluating and Enhancing Multimodal Agentic Search with Structured Long Reasoning Chains
Mar 01, 2026With the increasing demand for step-wise, cross-modal, and knowledge-grounded reasoning, multimodal large language models (MLLMs) are evolving beyond the traditional fixed retrieve-then-generate paradigm toward more sophisticated agentic multimodal retrieval-augmented generation (MM-RAG). Existing benchmarks, however, mainly focus on simplified QA with short retrieval chains, leaving adaptive planning and multimodal reasoning underexplored. We present MC-Search, the first benchmark for agentic MM-RAG with long, step-wise annotated reasoning chains spanning five representative reasoning structures. Each example specifies sub-questions, retrieval modalities, supporting facts, and intermediate answers, with fidelity ensured by HAVE (Hop-wise Attribution and Verification of Evidence), resulting in 3,333 high-quality examples averaging 3.7 hops. Beyond answer accuracy, MC-Search introduces new process-level metrics for reasoning quality, stepwise retrieval and planning accuracy. By developing a unified agentic MM-RAG pipeline, we benchmark six leading MLLMs and reveal systematic issues such as over- and under-retrieval and modality-misaligned planning. Finally, we introduce Search-Align, a process-supervised fine-tuning framework leveraging verified reasoning chains, showing that our data not only enables faithful evaluation but also improves planning and retrieval fidelity in open-source MLLMs.
FeDecider: An LLM-Based Framework for Federated Cross-Domain Recommendation
Feb 17, 2026Federated cross-domain recommendation (Federated CDR) aims to collaboratively learn personalized recommendation models across heterogeneous domains while preserving data privacy. Recently, large language model (LLM)-based recommendation models have demonstrated impressive performance by leveraging LLMs' strong reasoning capabilities and broad knowledge. However, adopting LLM-based recommendation models in Federated CDR scenarios introduces new challenges. First, there exists a risk of overfitting with domain-specific local adapters. The magnitudes of locally optimized parameter updates often vary across domains, causing biased aggregation and overfitting toward domain-specific distributions. Second, unlike traditional recommendation models (e.g., collaborative filtering, bipartite graph-based methods) that learn explicit and comparable user/item representations, LLMs encode knowledge implicitly through autoregressive text generation training. This poses additional challenges for effectively measuring the cross-domain similarities under heterogeneity. To address these challenges, we propose an LLM-based framework for federated cross-domain recommendation, FeDecider. Specifically, FeDecider tackles the challenge of scale-specific noise by disentangling each client's low-rank updates and sharing only their directional components. To handle the need for flexible and effective integration, each client further learns personalized weights that achieve the data-aware integration of updates from other domains. Extensive experiments across diverse datasets validate the effectiveness of our proposed FeDecider.
Graph homophily booster: Reimagining the role of discrete features in heterophilic graph learning
Feb 06, 2026Graph neural networks (GNNs) have emerged as a powerful tool for modeling graph-structured data. However, existing GNNs often struggle with heterophilic graphs, where connected nodes tend to have dissimilar features or labels. While numerous methods have been proposed to address this challenge, they primarily focus on architectural designs without directly targeting the root cause of the heterophily problem. These approaches still perform even worse than the simplest MLPs on challenging heterophilic datasets. For instance, our experiments show that 21 latest GNNs still fall behind the MLP on the Actor dataset. This critical challenge calls for an innovative approach to addressing graph heterophily beyond architectural designs. To bridge this gap, we propose and study a new and unexplored paradigm: directly increasing the graph homophily via a carefully designed graph transformation. In this work, we present a simple yet effective framework called GRAPHITE to address graph heterophily. To the best of our knowledge, this work is the first method that explicitly transforms the graph to directly improve the graph homophily. Stemmed from the exact definition of homophily, our proposed GRAPHITE creates feature nodes to facilitate homophilic message passing between nodes that share similar features. Furthermore, we both theoretically and empirically show that our proposed GRAPHITE significantly increases the homophily of originally heterophilic graphs, with only a slight increase in the graph size. Extensive experiments on challenging datasets demonstrate that our proposed GRAPHITE significantly outperforms state-of-the-art methods on heterophilic graphs while achieving comparable accuracy with state-of-the-art methods on homophilic graphs.
Agentic Reasoning for Large Language Models
Jan 18, 2026Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.
Graph Homophily Booster: Rethinking the Role of Discrete Features on Heterophilic Graphs
Sep 16, 2025Graph neural networks (GNNs) have emerged as a powerful tool for modeling graph-structured data. However, existing GNNs often struggle with heterophilic graphs, where connected nodes tend to have dissimilar features or labels. While numerous methods have been proposed to address this challenge, they primarily focus on architectural designs without directly targeting the root cause of the heterophily problem. These approaches still perform even worse than the simplest MLPs on challenging heterophilic datasets. For instance, our experiments show that 21 latest GNNs still fall behind the MLP on the Actor dataset. This critical challenge calls for an innovative approach to addressing graph heterophily beyond architectural designs. To bridge this gap, we propose and study a new and unexplored paradigm: directly increasing the graph homophily via a carefully designed graph transformation. In this work, we present a simple yet effective framework called GRAPHITE to address graph heterophily. To the best of our knowledge, this work is the first method that explicitly transforms the graph to directly improve the graph homophily. Stemmed from the exact definition of homophily, our proposed GRAPHITE creates feature nodes to facilitate homophilic message passing between nodes that share similar features. Furthermore, we both theoretically and empirically show that our proposed GRAPHITE significantly increases the homophily of originally heterophilic graphs, with only a slight increase in the graph size. Extensive experiments on challenging datasets demonstrate that our proposed GRAPHITE significantly outperforms state-of-the-art methods on heterophilic graphs while achieving comparable accuracy with state-of-the-art methods on homophilic graphs.
Model-Free Graph Data Selection under Distribution Shift
May 22, 2025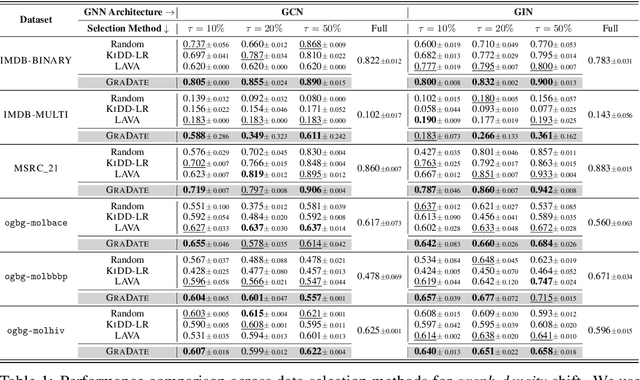
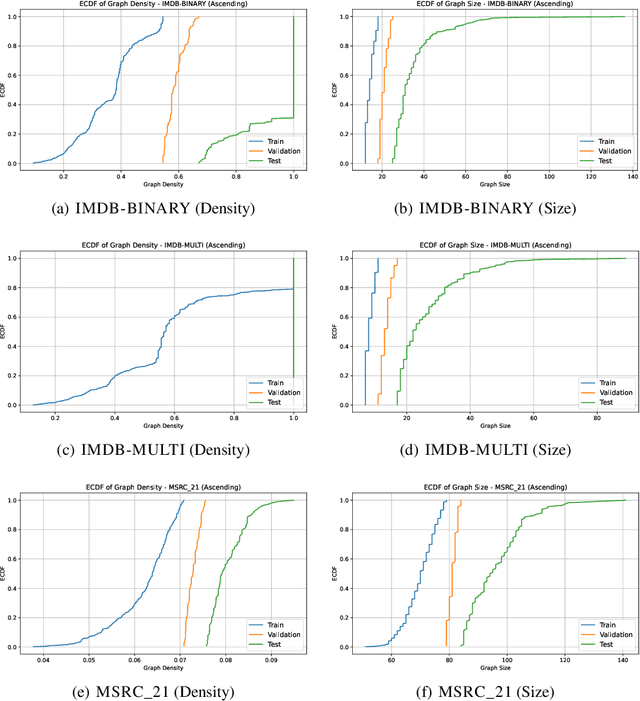
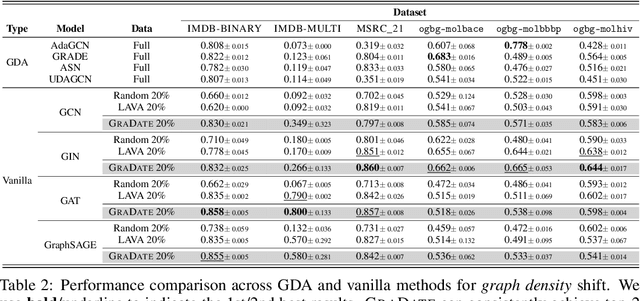
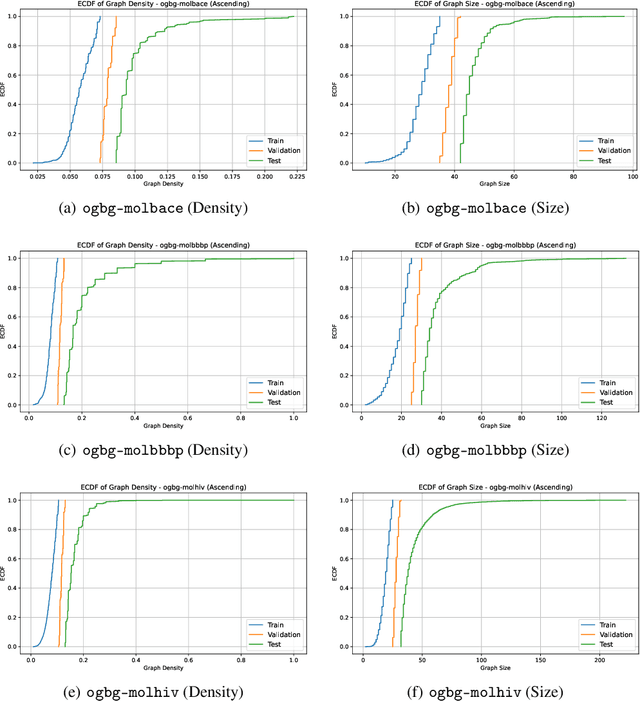
Graph domain adaptation (GDA) is a fundamental task in graph machine learning, with techniques like shift-robust graph neural networks (GNNs) and specialized training procedures to tackle the distribution shift problem. Although these model-centric approaches show promising results, they often struggle with severe shifts and constrained computational resources. To address these challenges, we propose a novel model-free framework, GRADATE (GRAph DATa sElector), that selects the best training data from the source domain for the classification task on the target domain. GRADATE picks training samples without relying on any GNN model's predictions or training recipes, leveraging optimal transport theory to capture and adapt to distribution changes. GRADATE is data-efficient, scalable and meanwhile complements existing model-centric GDA approaches. Through comprehensive empirical studies on several real-world graph-level datasets and multiple covariate shift types, we demonstrate that GRADATE outperforms existing selection methods and enhances off-the-shelf GDA methods with much fewer training data.
$\texttt{dattri}$: A Library for Efficient Data Attribution
Oct 06, 2024



Data attribution methods aim to quantify the influence of individual training samples on the prediction of artificial intelligence (AI) models. As training data plays an increasingly crucial role in the modern development of large-scale AI models, data attribution has found broad applications in improving AI performance and safety. However, despite a surge of new data attribution methods being developed recently, there lacks a comprehensive library that facilitates the development, benchmarking, and deployment of different data attribution methods. In this work, we introduce $\texttt{dattri}$, an open-source data attribution library that addresses the above needs. Specifically, $\texttt{dattri}$ highlights three novel design features. Firstly, $\texttt{dattri}$ proposes a unified and easy-to-use API, allowing users to integrate different data attribution methods into their PyTorch-based machine learning pipeline with a few lines of code changed. Secondly, $\texttt{dattri}$ modularizes low-level utility functions that are commonly used in data attribution methods, such as Hessian-vector product, inverse-Hessian-vector product or random projection, making it easier for researchers to develop new data attribution methods. Thirdly, $\texttt{dattri}$ provides a comprehensive benchmark framework with pre-trained models and ground truth annotations for a variety of benchmark settings, including generative AI settings. We have implemented a variety of state-of-the-art efficient data attribution methods that can be applied to large-scale neural network models, and will continuously update the library in the future. Using the developed $\texttt{dattri}$ library, we are able to perform a comprehensive and fair benchmark analysis across a wide range of data attribution methods. The source code of $\texttt{dattri}$ is available at https://github.com/TRAIS-Lab/dattri.
Efficient Ensembles Improve Training Data Attribution
May 27, 2024



Training data attribution (TDA) methods aim to quantify the influence of individual training data points on the model predictions, with broad applications in data-centric AI, such as mislabel detection, data selection, and copyright compensation. However, existing methods in this field, which can be categorized as retraining-based and gradient-based, have struggled with the trade-off between computational efficiency and attribution efficacy. Retraining-based methods can accurately attribute complex non-convex models but are computationally prohibitive, while gradient-based methods are efficient but often fail for non-convex models. Recent research has shown that augmenting gradient-based methods with ensembles of multiple independently trained models can achieve significantly better attribution efficacy. However, this approach remains impractical for very large-scale applications. In this work, we discover that expensive, fully independent training is unnecessary for ensembling the gradient-based methods, and we propose two efficient ensemble strategies, DROPOUT ENSEMBLE and LORA ENSEMBLE, alternative to naive independent ensemble. These strategies significantly reduce training time (up to 80%), serving time (up to 60%), and space cost (up to 80%) while maintaining similar attribution efficacy to the naive independent ensemble. Our extensive experimental results demonstrate that the proposed strategies are effective across multiple TDA methods on diverse datasets and models, including generative settings, significantly advancing the Pareto frontier of TDA methods with better computational efficiency and attribution efficacy.