 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraSS: Scalable Influence Function with Sparse Gradient Compression
May 25, 2025Gradient-based data attribution methods, such as influence functions, are critical for understanding the impact of individual training samples without requiring repeated model retraining. However, their scalability is often limited by the high computational and memory costs associated with per-sample gradient computation. In this work, we propose GraSS, a novel gradient compression algorithm and its variants FactGraSS for linear layers specifically, that explicitly leverage the inherent sparsity of per-sample gradients to achieve sub-linear space and time complexity. Extensive experiments demonstrate the effectiveness of our approach, achieving substantial speedups while preserving data influence fidelity. In particular, FactGraSS achieves up to 165% faster throughput on billion-scale models compared to the previous state-of-the-art baselines. Our code is publicly available at https://github.com/TRAIS-Lab/GraSS.
$\texttt{dattri}$: A Library for Efficient Data Attribution
Oct 06, 2024



Data attribution methods aim to quantify the influence of individual training samples on the prediction of artificial intelligence (AI) models. As training data plays an increasingly crucial role in the modern development of large-scale AI models, data attribution has found broad applications in improving AI performance and safety. However, despite a surge of new data attribution methods being developed recently, there lacks a comprehensive library that facilitates the development, benchmarking, and deployment of different data attribution methods. In this work, we introduce $\texttt{dattri}$, an open-source data attribution library that addresses the above needs. Specifically, $\texttt{dattri}$ highlights three novel design features. Firstly, $\texttt{dattri}$ proposes a unified and easy-to-use API, allowing users to integrate different data attribution methods into their PyTorch-based machine learning pipeline with a few lines of code changed. Secondly, $\texttt{dattri}$ modularizes low-level utility functions that are commonly used in data attribution methods, such as Hessian-vector product, inverse-Hessian-vector product or random projection, making it easier for researchers to develop new data attribution methods. Thirdly, $\texttt{dattri}$ provides a comprehensive benchmark framework with pre-trained models and ground truth annotations for a variety of benchmark settings, including generative AI settings. We have implemented a variety of state-of-the-art efficient data attribution methods that can be applied to large-scale neural network models, and will continuously update the library in the future. Using the developed $\texttt{dattri}$ library, we are able to perform a comprehensive and fair benchmark analysis across a wide range of data attribution methods. The source code of $\texttt{dattri}$ is available at https://github.com/TRAIS-Lab/dattri.
Pseudo-Non-Linear Data Augmentation via Energy Minimization
Oct 01, 2024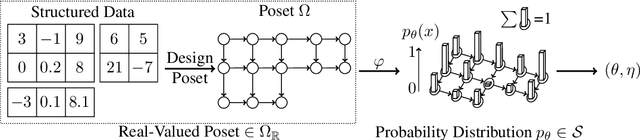

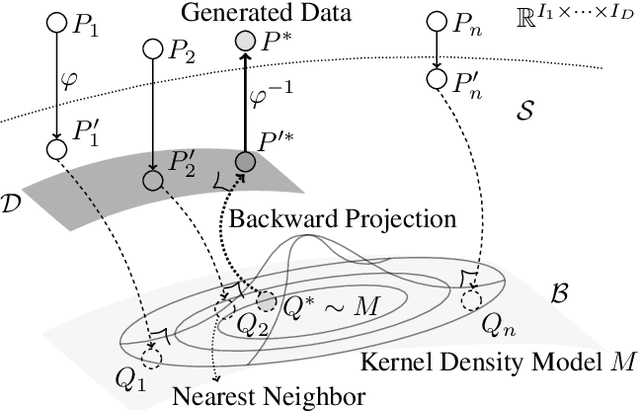

We propose a novel and interpretable data augmentation method based on energy-based modeling and principles from information geometry. Unlike black-box generative models, which rely on deep neural networks, our approach replaces these non-interpretable transformations with explicit, theoretically grounded ones, ensuring interpretability and strong guarantees such as energy minimization. Central to our method is the introduction of the backward projection algorithm, which reverses dimension reduction to generate new data. Empirical results demonstrate that our method achieves competitive performance with black-box generative models while offering greater transparency and interpretability.
Most Influential Subset Selection: Challenges, Promises, and Beyond
Sep 25, 2024How can we attribute the behaviors of machine learning models to their training data? While the classic influence function sheds light on the impact of individual samples, it often fails to capture the more complex and pronounced collective influence of a set of samples. To tackle this challenge, we study the Most Influential Subset Selection (MISS) problem, which aims to identify a subset of training samples with the greatest collective influence. We conduct a comprehensive analysis of the prevailing approaches in MISS, elucidating their strengths and weaknesses. Our findings reveal that influence-based greedy heuristics, a dominant class of algorithms in MISS, can provably fail even in linear regression. We delineate the failure modes, including the errors of influence function and the non-additive structure of the collective influence. Conversely, we demonstrate that an adaptive version of these heuristics which applies them iteratively, can effectively capture the interactions among samples and thus partially address the issues. Experiments on real-world datasets corroborate these theoretical findings, and further demonstrate that the merit of adaptivity can extend to more complex scenarios such as classification tasks and non-linear neural networks. We conclude our analysis by emphasizing the inherent trade-off between performance and computational efficiency, questioning the use of additive metrics such as the linear datamodeling score, and offering a range of discussions.
Adversarial Attacks on Data Attribution
Sep 09, 2024



Data attribution aims to quantify the contribution of individual training data points to the outputs of an AI model, which has been used to measure the value of training data and compensate data providers. Given the impact on financial decisions and compensation mechanisms, a critical question arises concerning the adversarial robustness of data attribution methods. However, there has been little to no systematic research addressing this issue. In this work, we aim to bridge this gap by detailing a threat model with clear assumptions about the adversary's goal and capabilities, and by proposing principled adversarial attack methods on data attribution. We present two such methods, Shadow Attack and Outlier Attack, both of which generate manipulated datasets to adversarially inflate the compensation. The Shadow Attack leverages knowledge about the data distribution in the AI applications, and derives adversarial perturbations through "shadow training", a technique commonly used in membership inference attacks. In contrast, the Outlier Attack does not assume any knowledge about the data distribution and relies solely on black-box queries to the target model's predictions. It exploits an inductive bias present in many data attribution methods - outlier data points are more likely to be influential - and employs adversarial examples to generate manipulated datasets. Empirically, in image classification and text generation tasks, the Shadow Attack can inflate the data-attribution-based compensation by at least 200%, while the Outlier Attack achieves compensation inflation ranging from 185% to as much as 643%.
Towards Reliable Empirical Machine Unlearning Evaluation: A Game-Theoretic View
Apr 17, 2024



Machine unlearning is the process of updating machine learning models to remove the information of specific training data samples, in order to comply with data protection regulations that allow individuals to request the removal of their personal data. Despite the recent development of numerous unlearning algorithms, reliable evaluation of these algorithms remains an open research question. In this work, we focus on membership inference attack (MIA) based evaluation, one of the most common approaches for evaluating unlearning algorithms, and address various pitfalls of existing evaluation metrics that lack reliability. Specifically, we propose a game-theoretic framework that formalizes the evaluation process as a game between unlearning algorithms and MIA adversaries, measuring the data removal efficacy of unlearning algorithms by the capability of the MIA adversaries. Through careful design of the game, we demonstrate that the natural evaluation metric induced from the game enjoys provable guarantees that the existing evaluation metrics fail to satisfy. Furthermore, we propose a practical and efficient algorithm to estimate the evaluation metric induced from the game, and demonstrate its effectiveness through both theoretical analysis and empirical experiments. This work presents a novel and reliable approach to empirically evaluating unlearning algorithms, paving the way for the development of more effective unlearning techniques.
Travel the Same Path: A Novel TSP Solving Strategy
Oct 12, 2022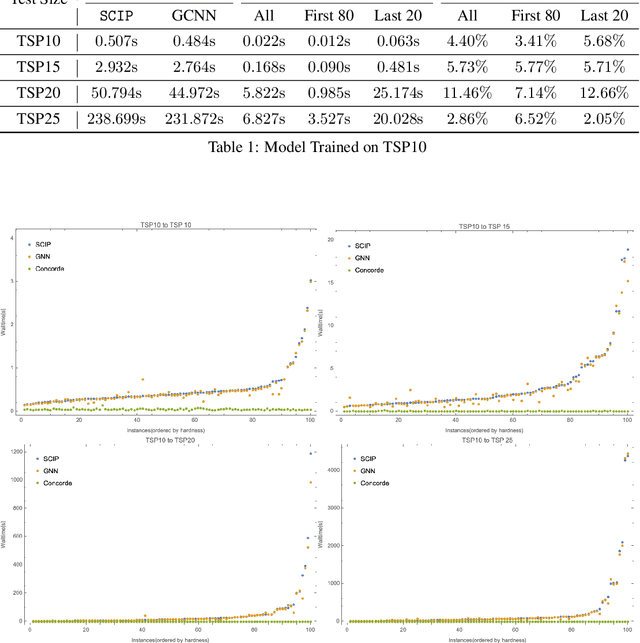
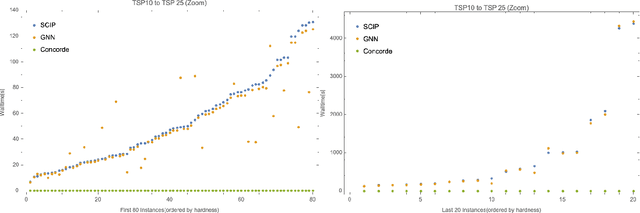


In this paper, we provide a novel strategy for solving Traveling Salesman Problem, which is a famous combinatorial optimization problem studied intensely in the TCS community. In particular, we consider the imitation learning framework, which helps a deterministic algorithm making good choices whenever it needs to, resulting in a speed up while maintaining the exactness of the solution without suffering from the unpredictability and a potential large deviation. Furthermore, we demonstrate a strong generalization ability of a graph neural network trained under the imitation learning framework. Specifically, the model is capable of solving a large instance of TSP faster than the baseline while has only seen small TSP instances when training.