 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanStudy-Bench: Towards AI Agent Design for Participant Simulation
Jan 31, 2026Large language models (LLMs) are increasingly used as simulated participants in social science experiments, but their behavior is often unstable and highly sensitive to design choices. Prior evaluations frequently conflate base-model capabilities with experimental instantiation, obscuring whether outcomes reflect the model itself or the agent setup. We instead frame participant simulation as an agent-design problem over full experimental protocols, where an agent is defined by a base model and a specification (e.g., participant attributes) that encodes behavioral assumptions. We introduce HUMANSTUDY-BENCH, a benchmark and execution engine that orchestrates LLM-based agents to reconstruct published human-subject experiments via a Filter--Extract--Execute--Evaluate pipeline, replaying trial sequences and running the original analysis pipeline in a shared runtime that preserves the original statistical procedures end to end. To evaluate fidelity at the level of scientific inference, we propose new metrics to quantify how much human and agent behaviors agree. We instantiate 12 foundational studies as an initial suite in this dynamic benchmark, spanning individual cognition, strategic interaction, and social psychology, and covering more than 6,000 trials with human samples ranging from tens to over 2,100 participants.
PrivacyReasoner: Can LLM Emulate a Human-like Privacy Mind?
Jan 14, 2026This paper introduces PRA, an AI-agent design for simulating how individual users form privacy concerns in response to real-world news. Moving beyond population-level sentiment analysis, PRA integrates privacy and cognitive theories to simulate user-specific privacy reasoning grounded in personal comment histories and contextual cues. The agent reconstructs each user's "privacy mind", dynamically activates relevant privacy memory through a contextual filter that emulates bounded rationality, and generates synthetic comments reflecting how that user would likely respond to new privacy scenarios. A complementary LLM-as-a-Judge evaluator, calibrated against an established privacy concern taxonomy, quantifies the faithfulness of generated reasoning. Experiments on real-world Hacker News discussions show that \PRA outperforms baseline agents in privacy concern prediction and captures transferable reasoning patterns across domains including AI, e-commerce, and healthcare.
Measuring Fine-Grained Relatedness in Multitask Learning via Data Attribution
May 27, 2025Measuring task relatedness and mitigating negative transfer remain a critical open challenge in Multitask Learning (MTL). This work extends data attribution -- which quantifies the influence of individual training data points on model predictions -- to MTL setting for measuring task relatedness. We propose the MultiTask Influence Function (MTIF), a method that adapts influence functions to MTL models with hard or soft parameter sharing. Compared to conventional task relatedness measurements, MTIF provides a fine-grained, instance-level relatedness measure beyond the entire-task level. This fine-grained relatedness measure enables a data selection strategy to effectively mitigate negative transfer in MTL. Through extensive experiments, we demonstrate that the proposed MTIF efficiently and accurately approximates the performance of models trained on data subsets. Moreover, the data selection strategy enabled by MTIF consistently improves model performance in MTL. Our work establishes a novel connection between data attribution and MTL, offering an efficient and fine-grained solution for measuring task relatedness and enhancing MTL models.
Towards Reliable Empirical Machine Unlearning Evaluation: A Game-Theoretic View
Apr 17, 2024



Machine unlearning is the process of updating machine learning models to remove the information of specific training data samples, in order to comply with data protection regulations that allow individuals to request the removal of their personal data. Despite the recent development of numerous unlearning algorithms, reliable evaluation of these algorithms remains an open research question. In this work, we focus on membership inference attack (MIA) based evaluation, one of the most common approaches for evaluating unlearning algorithms, and address various pitfalls of existing evaluation metrics that lack reliability. Specifically, we propose a game-theoretic framework that formalizes the evaluation process as a game between unlearning algorithms and MIA adversaries, measuring the data removal efficacy of unlearning algorithms by the capability of the MIA adversaries. Through careful design of the game, we demonstrate that the natural evaluation metric induced from the game enjoys provable guarantees that the existing evaluation metrics fail to satisfy. Furthermore, we propose a practical and efficient algorithm to estimate the evaluation metric induced from the game, and demonstrate its effectiveness through both theoretical analysis and empirical experiments. This work presents a novel and reliable approach to empirically evaluating unlearning algorithms, paving the way for the development of more effective unlearning techniques.
Graph Learning Indexer: A Contributor-Friendly and Metadata-Rich Platform for Graph Learning Benchmarks
Dec 08, 2022
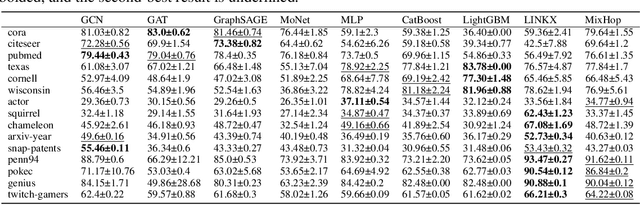

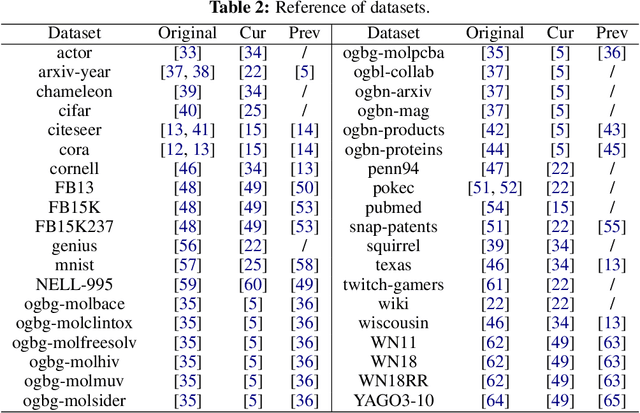
Establishing open and general benchmarks has been a critical driving force behind the success of modern machine learning techniques. As machine learning is being applied to broader domains and tasks, there is a need to establish richer and more diverse benchmarks to better reflect the reality of the application scenarios. Graph learning is an emerging field of machine learning that urgently needs more and better benchmarks. To accommodate the need, we introduce Graph Learning Indexer (GLI), a benchmark curation platform for graph learning. In comparison to existing graph learning benchmark libraries, GLI highlights two novel design objectives. First, GLI is designed to incentivize \emph{dataset contributors}. In particular, we incorporate various measures to minimize the effort of contributing and maintaining a dataset, increase the usability of the contributed dataset, as well as encourage attributions to different contributors of the dataset. Second, GLI is designed to curate a knowledge base, instead of a plain collection, of benchmark datasets. We use multiple sources of meta information to augment the benchmark datasets with \emph{rich characteristics}, so that they can be easily selected and used in downstream research or development. The source code of GLI is available at \url{https://github.com/Graph-Learning-Benchmarks/gli}.